Node.js出现后,爬虫便不再是后台语言如PHP,Python的专利了,尽管在处理大量数据时的表现仍然不如后台语言,但是Node.js异步编程的特性可以让我们在最少的cpu开销下轻松完成高并发的爬取。另外由于现在许多网站都有了反爬虫手段,对付这些手段最合适的当然是可以在浏览器中直接运行的JS,这也使得基于Node.js的爬虫技术越来越受重视。
今天就来讲一讲基于Node.js的爬虫入门,以爬虫程序中万年躺枪的豆瓣电影网为例(豆瓣的网站不需要登陆也可以查看大部分内容,不用设置cookie,且页面结构相对简单,反爬虫手段不多,很适合拿来入门),爬取某部电影的所有影评,简要介绍爬虫的一些基本知识。
准备
因为是入门,本文使用原生的语法,所使用的第三方库只有两个:mongoose和cheerio。
cheerio是爬虫中必备的神器,mongoose则是一个关于mongoDB数据库操作的库,主要是方便将爬到的数据存入数据库中,本文不做过多讲解。
cheerio
先安装cheerio
cheerio的作用主要使用jQuery的语法来解析得到html文档,主要用法如下
1 2 3
|
const cheerio = require('cheerio'); let $ = cheerio.load("<p>Hello world!</p>"); $('p').text(); // Hello world!
|
它基本保留了jQuery的核心部分,包括jQuery的一些工具。
关于cheerio的更详细的内容请参考github。
分析网站
写爬虫时最重要的工作就是分析网站,我们先打开豆瓣电影网。
本文以经典电影《肖申克的救赎》为例,爬取全部4210篇影评并保存到mongoDB数据库(部分被折叠影评不获取,实际大概3800篇)。
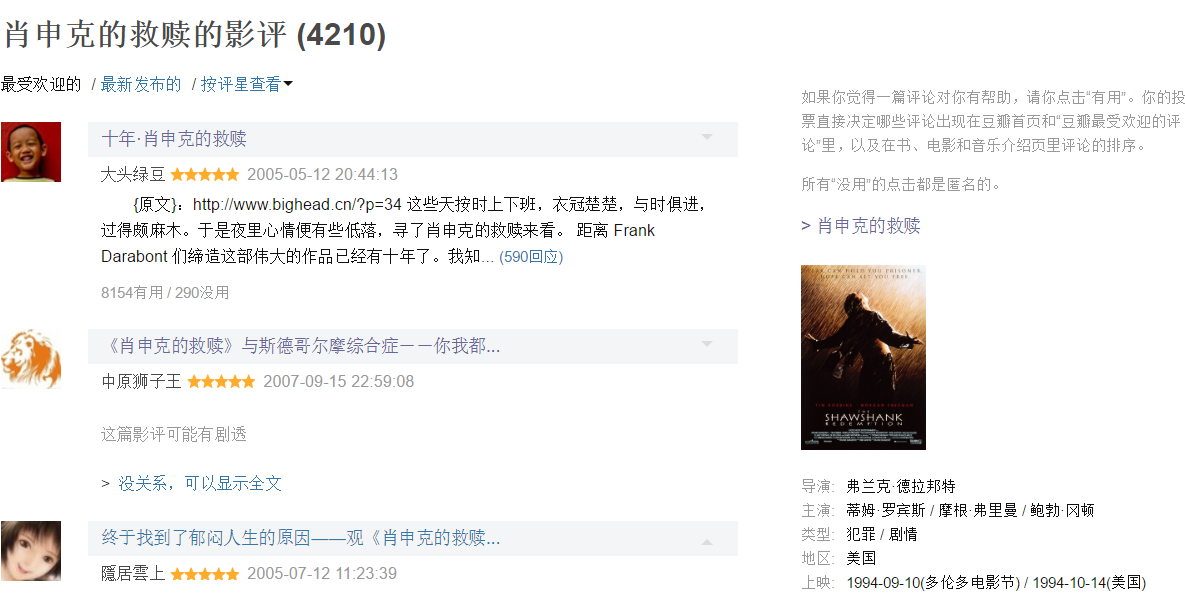
F12打开chrome开发者工具,查看元素,发现整个页面的内容基本都是从这个接口返回的。
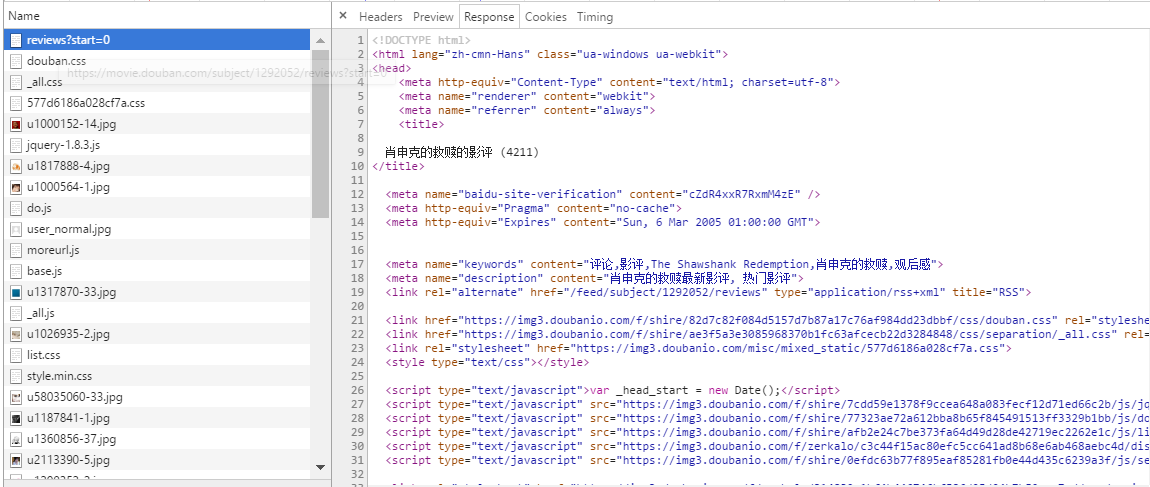
接口的路径为
1
|
/subject/1292052/reviews?start=0
|
url中的start参数显然是用来控制当前显示的是第几页的参数,每页返回的影评数目为20个。
分析网页的结构

可以从里面得到文章的id,作者,标题和内容。
继续分析发现当前这个页面中的影评内容只有一些摘要,点击查看全文时发现网页发起了一个Ajax请求。

可以看到,这个接口以JSON的格式返回了文章的内容,点赞人数等,不过文章的内容是html格式的,我们在存储时需要进行一些处理。
接口的路径为
1000369就是文章的id。
这样看来,我们的爬虫程序就需要分两次爬取了,第一次先获得所有文章的id及作者,标题,第二次则根据文章的id来获取文章的内容。
开始
爬虫代码如下,运行的node版本为6.9.1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72
|
// 依赖的模块 const https = require('https'), mongoose = require('mongoose'), cheerio = require('cheerio'); mongoose.connect('mongodb://localhost/article'); // 链接数据库 const schema = new mongoose.Schema({ // 创建schema uuid: Number, title: String, author: String, content: String }); let model = mongoose.model('article', schema); let host = 'movie.douban.com'; let agent = new https.Agent({ // 创建https代理 host, rejectUnauthorized: false }); const getList = (start) => { // 根据start的值发起请求 let path = `/subject/1292052/reviews?start=${start}`; let req = https.request({ host, path, agent, port: 443, method: 'GET' }, res => { let data = ''; res.on('data', (chunk) =>{ data += chunk; }); res.on('end', () =>{ handleData(data); }) }); const handleData = data =>{ // 得到网页html后根据网页进行的程序 let $ = cheerio.load(data); $('div.review-item').each((index, item) =>{ let _item = $(item), uuid = _item.attr('id'), title = _item.find('a.title-link').text(), author = _item.find('.author span').text(); model.create({ uuid, title, author, content: '' }) }); }; req.on('error', (err) =>{ console.log(err); }); req.end(); }; // 运行 for(let i=0;i < 196; i++){ getList(i*20); }
|
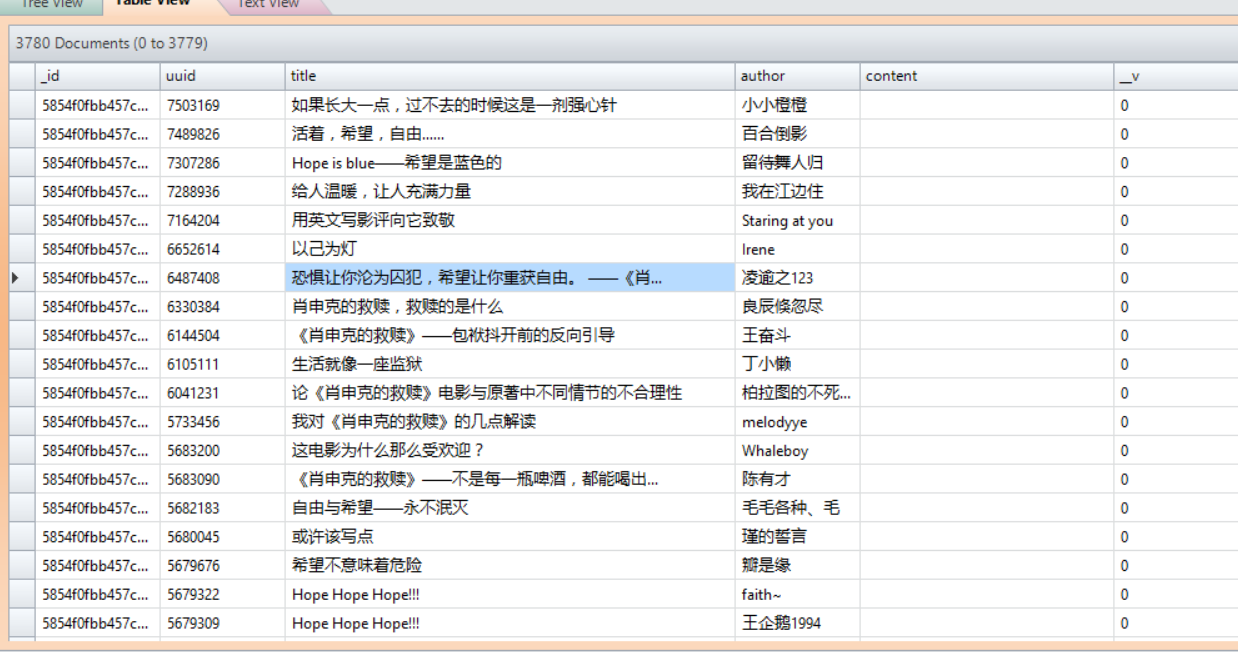
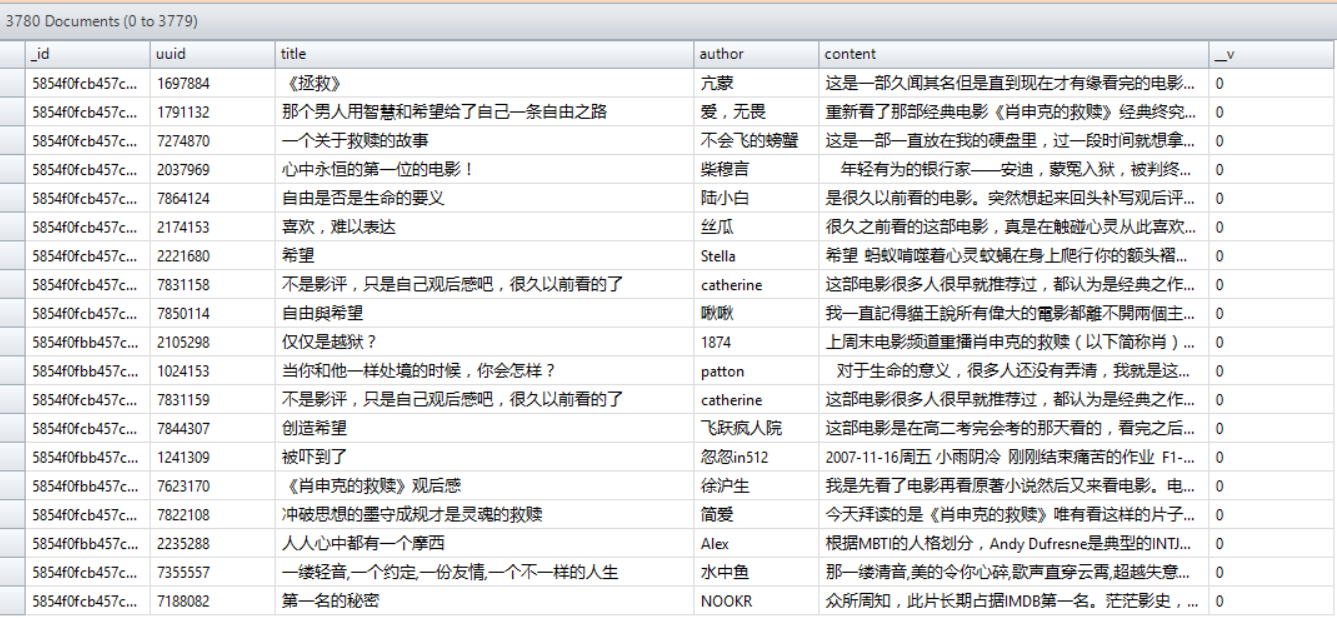
详细过程在代码中都已经注释了,运行后的数据库如下
解决title问题
数据库中马上多了3000多条数据,真是亦可赛艇。但是我们发现,其中有一些数据数据的title字段不全(以”…”结尾),我们回去看网页,发现豆瓣渲染的网页是进行过截字处理的。
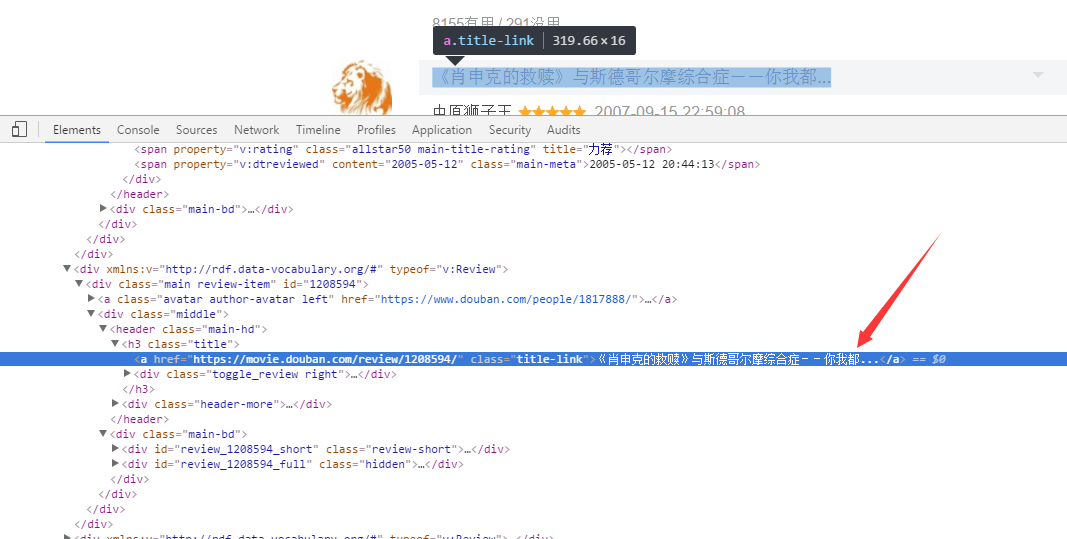
没办法,只能乖乖的进入详情页面获取文章标题了。
将刚刚获得的数据全部取出来,通过正则
来判断是否为不全的title,并进行请求,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49
|
model.find({}, (err, data) => { // 从数据库获取所有数据 data.forEach(item => { if (item.title.length > 20 && /\.{3}$/.test(item.title)) { // 判断是否为不全的数据 getTitle(item.uuid, title =>{ console.log(title, item.uuid); model.update({_id: item._id}, {$set: {title}}, (err, info) =>{ if(err){ console.log(err); } else { console.log(info); } }) }); } }); }); let host = 'movie.douban.com'; let agent = new https.Agent({ host, rejectUnauthorized: false }); const getTitle = (uuid, callback) => { // 获取title let path = `/review/${uuid}/`; let req = https.request({ host, path, agent, port: 443, method: 'GET' }, res => { let data = ''; res.on('data', chunk => { data += chunk; }); res.on('end', () => { let $ = cheerio.load(data); callback($('#content span[property="v:summary"]').text()); }) }); req.end(); };
|
运行后数据库中就没有title字段不全的情况了。

获取文章全部内容
这里因为时间和存储空间的关系,就只获取前一百篇文章的内容。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41
|
model.find({}, (err, data) => { // 从数据库获取所有数据 data.forEach((item, index) => { if (index > 100) { // 只获取前100篇的内容 return; } if (item.content == '') { getContent(item.uuid, content => { model.update({_id: item._id}, {$set: {content}}, (err, info) =>{ if(err){ console.log(err); } else { console.log(info); } }) }) } }) }); const getContent = (id, callback) => { // 获取文章内容 let path = `/j/review/${id}/full`; let req = https.request({ host, path, agent, port: 443, method: 'GET' }, res => { let data = ''; res.on('data', chunk => { data += chunk; }); res.on('end', () => { data = JSON.parse(data); callback(data.html.replace(/ /g, ' ').replace(/<br>/g, '\r\n')); }) }); req.end(); };
|
运行后的数据库如图
结语
本文只是对爬虫程序的入门级别,实际上,爬虫运行时还需要考虑很多问题,如对抗反爬虫技术,设置cookies,程序运行效率等等。对爬虫感兴趣的同学可以深入了解http及https请求、网络安全、算法数据结构方面的知识。









{kind=link}