1.介绍 #
- 正则表达式是一种用于描述和匹配文本模式的强大工具
- 它是由一系列字符组成的模式,这些字符可以是普通字符或特殊字符
- 正则表达式通过定义一个特定的模式,可以用来在文本中搜索、替换或验证符合该模式的字符串
2.应用场景 #
- 表单验证:在网站或应用中,用户需要输入各种信息,如电子邮件地址、手机号码、密码等。正则表达式可以用于验证用户输入的数据是否符合预期的格式,从而提高数据的准确性和安全性
- 文本搜索:正则表达式可以帮助我们在大量文本中快速地定位到符合特定模式的字符串,例如在日志文件中查找特定格式的错误信息,或在网页源代码中提取所有的链接地址
- 文本替换:正则表达式可以用于查找并替换文本中符合特定模式的部分。例如,将文本中的所有电话号码格式统一,或替换特定词汇以避免敏感词
3. 正则对象 #
- 在 JavaScript 中,正则表达式对象(RegExp)是一个内置对象,用于表示和操作正则表达式
- 它们提供了一种灵活的方式来搜索、匹配、替换和分割文本
- regulex是一个可以帮助你理解和调试正则表达式的在线工具
- regexper
3.1 创建正则对象 #
- RegExp
pattern 正则表达式的文本flags 标志
/pattern/flags
new RegExp(pattern[, flags])
3.1.1 字面量表示法 #
const regex = /apple/;
3.1.2 构造函数表示法 #
const regex = new RegExp("apple");
3.2 区别 #
3.2.1 变量 #
const regexpSource = "apple"
const regexp1 = /regexpSource/;
const regexp2 = new RegExp(regexpSource)
3.2.2 转义 #
- 在 JavaScript 中,反斜杠(\)是一个转义字符,用于转义字符串中的特殊字符
| 特殊字符 |
字符含义 |
示例 |
| \ |
转义\ |
\\ |
| ' |
单引号 |
\' |
| " |
双引号 |
\" |
| \n |
换行符 |
\n |
| \r |
回车符 |
\r |
| \t |
制表符 |
\t |
| \uXXXX |
Unicode 字符 |
\u03A9 |
const regexp2 = new RegExp('\'')
const regexp3 = new RegExp("\"")
const regexp4 = new RegExp("\n")
const regexp5 = new RegExp("\r")
const regexp1 = new RegExp("\\d")
3.3 方法和属性 #
3.3.1 test #
- 用于测试字符串是否与正则表达式匹配
test 方法返回一个布尔值:如果找到匹配项,返回 true;否则返回 false- JS的正则对象的test()方法也会修改lastIndex属性的值,lastIndex属性是一个可读写属性,用于设置下一次匹配的起始位置,如果匹配失败,lastIndex属性会被重置为0
const regex = /apple/;
const str = "apple";
const result = regex.test(str);
console.log(result);
const str = 'hello hello ';
const regexp1 = /hello/;
let result;
console.log(regexp1.lastIndex);
result = regexp1.test(str);
console.log(result);
console.log(regexp1.lastIndex);
result = regexp1.test(str);
console.log(result);
console.log(regexp1.lastIndex);
result = regexp1.test(str);
console.log(result);
console.log(regexp1.lastIndex);
const regexp2 = /hello/g;
console.log(regexp2.lastIndex);
result = regexp2.test(str);
console.log(result);
console.log(regexp2.lastIndex);
result = regexp2.test(str);
console.log(result);
console.log(regexp2.lastIndex);
result = regexp2.test(str);
console.log(result);
console.log(regexp2.lastIndex);
3.3.2 global #
- 正则表达式对象(RegExp 实例)的 g 标志表示全局匹配模式
- 当使用这个标志时,正则表达式将会匹配目标字符串中的所有可能匹配项,而不是只匹配第一个匹配项
- global:布尔值,表示正则表达式对象是否具有全局标志(g)
const regex1 = /hello/;
const regex2 = /hello/g;
console.log(regex2.global);
const str = "hello hello";
const result1 = str.match(regex1);
console.log(result1);
const result2 = str.match(regex2);
console.log(result2);
3.3.3 ignoreCase #
- ignoreCase:布尔值,表示正则表达式对象是否具有不区分大小写标志(i)
- 要使用
i 标志,可以在创建正则表达式对象时将其添加到正则表达式字面量表示法的末尾,或将其作为 RegExp 构造函数的第二个参数
- 以下是两种创建带有 i 标志的正则表达式对象的方法
const regex1 = /apple/;
console.log('regex1.ignoreCase', regex1.ignoreCase);
const regex2 = /apple/i;
console.log('regex2.ignoreCase', regex2.ignoreCase);
const str = "Apple";
const result1 = regex1.test(str);
console.log('result1', result1);
const result2 = regex2.test(str);
console.log('result2', result2);
3.3.4 multiline #
- 正则表达式对象(RegExp 实例)的
m 标志表示“多行模式”
- 当使用这个标志时,正则表达式将会在跨越多行文本时匹配每一行的开头和结尾
multiline:布尔值,表示正则表达式对象是否具有多行标志(m)
const regex1 = /^world/;
const regex2 = /^world/m;
console.log(regex2.multiline);
const str = "hello \nworld you";
console.log(regex1.test(str));
console.log(regex2.test(str));
3.3.5 exec #
- RegExp 实例的 exec 方法用于在字符串中执行正则表达式匹配操作,并返回匹配结果的详细信息
- 如果找到了匹配项,exec 方法会返回一个数组,其中包含匹配到的字符串、匹配项的位置信息以及其他有关匹配项的详细信息。如果没有找到匹配项,exec 方法将返回 null
lastIndex 属性是一个数字,指示下一次正则表达式匹配操作应该从字符串的哪个位置开始。在具有 g 标志的正则表达式上调用 exec 方法时,lastIndex 属性的值会自动更新。当匹配项被找到时,lastIndex 属性将被设置为匹配项的结尾位置(即匹配项的下一个位置)。如果没有找到匹配项,lastIndex 属性将被重置为 0- 需要注意的是,如果正则表达式对象没有 g 标志,那么 lastIndex 属性将不会被更新
const regex = /hello/;
const str = "hello";
const result = regex.exec(str);
console.log(result);
const regex = /hello/g;
const str = "hello hello";
const result1 = regex.exec(str);
console.log(regex.lastIndex);
console.log(result1);
const result2 = regex.exec(str);
console.log(result2);
3.3.6 source #
const regex = /abc/i;
console.log(regex.source);
3.3.7 flags #
const regex = /abc/gi;
console.log(regex.flags);
3.2.8 dotAll #
- 布尔值,表示正则表达式对象是否具有 dotAll 标志(s)。当设置此标志时,. 特殊字符将匹配任何字符,包括换行符
const regex1 = /abc./;
console.log(regex1.dotAll);
const regex2 = /abc./s;
console.log(regex2.dotAll);
console.log(regex1.test('abc\ndef'));
console.log(regex2.test('abc\ndef'));
3.3.10 sticky #
- 布尔值,表示正则表达式对象是否具有粘性标志(y)。当设置此标志时,正则表达式将从上次匹配结束的位置继续匹配
- 在普通模式下,正则表达式的匹配会从字符串的起始位置开始
- 而在粘性模式下,正则表达式的匹配会从上一次匹配成功的位置开始
- 全局标志用于在整个字符串中查找所有匹配项,而粘性标志要求匹配必须从 lastIndex 位置开始
const regexp = /\d/y;
console.log(regexp.sticky);
const str = '1a2b3';
let result;
result = regexp.exec(str);
console.log(result);
console.log(regexp.lastIndex);
result = regexp.exec(str);
console.log(result);
console.log(regexp.lastIndex);
result = regexp.exec(str);
console.log(result);
console.log(regexp.lastIndex);
3.3.11 lastIndex #
- 表示下一次匹配开始的字符串索引。当正则表达式对象具有全局(g)或粘性(y)标志时,它会在多次匹配中更新
const regex = /abc/g;
const str = "abc abc";
regex.exec(str);
console.log(regex.lastIndex);
3.3.12 hasIndices #
- 如果 d 标志被使用,则 RegExp.prototype.hasIndices 的值是 true;否则是 false
- d 标志表示正则表达式匹配的结果应该包含每个捕获组子字符串开始和结束的索引
const regex1 = new RegExp('a(bc)(de)f', 'd');
console.log(regex1.hasIndices);
console.log(regex1.exec('abcdef'));
4.特殊字符 #
4.1 ^ #
const str1 = "hello world";
const regexp1 = /^hello/;
const result1 = regexp1.exec(str1);
console.log(result1);
4.2 $ #
const str1 = "hello world";
const regexp1 = /world$/;
const result1 = regexp1.exec(str1);
console.log(result1);
4.3 单词边界 #
- 正则表达式中的单词边界(word boundary)是一个特殊的元字符,表示一个单词和非单词字符之间的位置
- 非单词可以是开始结束、符号(中文符号、英文符号、空格、制表符、换行、汉字)
- 单词边界在正则表达式中用
\b表示
- 注意,单词边界本身不匹配任何字符,它只是一个位置指示器
| 特殊符号 |
含义 |
示例代码 |
| \b |
单词边界 |
/\\bword\\b/.test("This is a word") |
| \B |
非单词边界 |
/\\Bword\\B/.test("This is awordb") |
const str1 = "hello world you";
const regexp1 = /\bworld\b/;
const result1 = regexp1.exec(str1);
console.log(result1);
4.4 [] #
- [] 表示字符集合
- [] 中的大部分特殊字符都失去了特殊含义,因此通常不需要转义,
.、%、+ 和 - 均被视为普通字符
- 以下是正则表达式字符类中需要转义的字符:
- ^:如果它出现在字符类的开头,表示取反。如果您需要匹配一个 ^ 字符,可以将其放在字符类的其他位置,或在开头使用 \^ 进行转义
- -:如果它出现在字符类的中间,表示范围。如果您需要匹配一个 - 字符,可以将其放在字符类的开头或结尾,或在任意位置使用 - 进行转义
- ]:如果它出现在字符类的中间,表示字符类的结束。如果您需要匹配一个 ] 字符,请使用 ] 进行转义
| 特殊符号 |
含义 |
示例代码 |
| [abc] |
可能是字符 "a"、"b" 或 "c" 的字符 |
/a[abc]d/ 匹配 "aad"、"abd" 或 "acd" |
| [^abc] |
不是字符 "a"、"b" 或 "c" 的字符 |
/[^abc]/ 匹配任意一个不是 "a"、"b" 或 "c" 的字符 |
| [a-z] |
从 "a" 到 "z" 中的任意一个小写字母 |
/[a-z]/ 匹配任意一个小写字母 |
| [A-Z] |
从 "A" 到 "Z" 中的任意一个大写字母 |
/[A-Z]/ 匹配任意一个大写字母 |
| [a-zA-Z] |
包括小写和大写字母的任意一个字母字符 |
/[a-zA-Z]/ 匹配任意一个字母字符 |
| [0-9] |
从 "0" 到 "9" 中的任意一个数字字符 |
/[0-9]/ 匹配任意一个数字字符 |
const regexp1 = /[abc]/;
const str1 = "abcd";
const result1 = regexp1.exec(str1);
console.log('result1', result1);
const regexp2 = /[^abc]/;
const str2 = "abcd";
const result2 = regexp2.exec(str2);
console.log('result2', result2);
const regexp3 = /[^a-z]/;
const str3 = "aBcd";
const result3 = regexp3.exec(str3);
console.log('result3', result3);
const regexp4 = /[^A-Z]/;
const str4 = "aBcD";
const result4 = regexp4.exec(str4);
console.log('result4', result4);
const regexp5 = /[^a-zA-Z]/;
const str5 = "aBcd123";
const result5 = regexp5.exec(str5);
console.log('result5', result5);
const regexp6 = /[^0-9]/;
const str6 = "abcd123";
const result6 = regexp6.exec(str6);
console.log('result6', result6);
4.5 \d #
const str1 = "a1b";
const regexp1 = /\d/g;
console.log(regexp1.exec(str1));
4.6 \D #
const str2 = "a1b";
const regexp2 = /\D/g;
console.log(regexp2.exec(str2));
4.7 \w #
4.8 \W #
4.9 \s #
const str5 = "_1b @#";
const regexp5 = /\s/g;
console.log(regexp5.exec(str5));
4.10 \S #
4.11 . #
- 是正则表达式中最常用的元字符之一,用于匹配任意一个字符(除了换行符 \n 之外的任何字符)
- 匹配的字符除了换行符之外,包括空格、制表符等
- 包括换行符在内,可以使用正则表达式中的 [\s\S]、[\d\D] 或 [\w\W] 等字符集合
let regexp1 = /he..o/;
console.log(regexp1.exec('hello'));
4.12 转义 #
- 在正则表达式中
\ 用于转义后面的字符,使其不再具有原有的特殊含义,而变成普通字符
\ 匹配反斜杠字符 . 匹配任意单个字符(除了换行符 \n)/ 匹配正斜杠字符 * 匹配前面的字符(子表达式)出现 0 次或多次+ 匹配前面的字符(子表达式)出现 1 次或多次? 匹配前面的字符(子表达式)出现 0 次或 1 次( 匹配左括号字符 [ 匹配左方括号字符
需要注意的是,\ 本身也是一个转义字符,在正则表达式中需要使用两个反斜杠 \ 来匹配一个反斜杠字符
const str1 = "a.b";
const regexp1 = /\./g;
console.log(regexp1.exec(str1));
5. 量词 #
| 特殊符号 |
含义 |
示例代码 |
* |
匹配前面的子表达式零次或多次 |
/a*/ |
+ |
匹配前面的子表达式一次或多次 |
/a+/ |
? |
匹配前面的子表达式零次或一次 |
/a?/ |
{n} |
匹配前面的子表达式恰好n次 |
/a{3}/ |
{n,} |
匹配前面的子表达式至少n次 |
/a{2,}/ |
{n,m} |
匹配前面的子表达式至少n次,至多m次 |
/a{2,4}/ |
5.1 * #
const str1 = "aaa";
const regexp1 = /^aaab*$/g;
const result1 = regexp1.exec(str1);
console.log(result1);
5.2 + #
const str2 = "aaab";
const regexp2 = /^aaab+$/g;
const result2 = regexp2.exec(str2);
console.log(result2);
5.3 ? #
const str3 = "aaabbb";
const regexp3 = /^aaab?/g;
const result3 = regexp3.exec(str3);
console.log(result3);
5.4 {n} #
5.5 {n,} #
const str5 = "aaabbb";
const regexp5 = /^aaab{1,}/g;
const result5 = regexp5.exec(str5);
console.log(result5);
5.6 {n,m} #
const str6 = "aaabbb";
const regexp6 = /^aaab{1,3}/g;
const result6 = regexp6.exec(str6);
console.log(result6);
5.7 懒惰匹配 #
- 量词默认采用的是贪婪匹配(Greedy Quantifier)
- 贪婪匹配是指尽可能多地匹配字符,直到无法匹配为止
.* 匹配任意字符(包括换行符)任意次数,直到遇到 div 为止- 因为量词采用的是贪婪匹配,所以它会尽可能多地匹配字符,包括跨越多个标签的情况
- 想要只匹配一个 HTML 标签之间的内容,可以使用懒惰匹配(Lazy Quantifier)
- 懒惰匹配是指尽可能少地匹配字符,直到能够匹配为止。在 JavaScript 正则表达式中,可以在量词后面添加 ? 来表示懒惰匹配
const str = '<div>Content1</div><div>Content2</div>';
const regexp = /<div>(.*)<\/div>/g;
console.log(str.match(regexp));
const str = '<div>Content 1</div><div>Content 2</div>';
const regexp = /<div>(.*?)<\/div>/g;
console.log(str.match(regexp));
6. 分组 #
- 在JavaScript中,可以使用圆括号()来创建分组
6.1 组合 #
- 在正则表达式中,分组允许我们将子表达式组合在一起,以便对整个组应用量词或其他操作
const str1 = "ababab";
const regexp1 = /(ab){3}/;
const result1 = regexp1.exec(str1);
console.log(result1);
6.2 捕获 #
const str1 = "<div>(.+)</div>";
const regexp1 = /<div>(.+)<\/div>/;
const result1 = regexp1.exec(str1);
console.log(result1);
6.3 $ #
- RegExp对象的属性$1-$9是一个只读属性,用于获取正则表达式中对应的捕获组的值
- 当匹配成功时,如果正则表达式中包含捕获组,那么每个捕获组都会将匹配到的内容保存到一个特殊的内部变量中,这些变量分别称为$1、$2、$3、$4等等
const regexp = /(\w+)\s(\w+)/;
const str = 'hello world';
const result = regexp.exec(str);
console.log(result);
console.log(result[1]);
console.log(result[2]);
console.log(RegExp.$1);
console.log(RegExp.$2);
6.4 | #
- | 表示逻辑 OR,用于匹配多个选项中的任意一个。例如,正则表达式 cat|dog 可以匹配字符串中的 "cat" 或 "dog"
const regexp = /(hello|world)/;
const str1 = "hello";
const result1 = regexp.exec(str1);
console.log(result1);
const str2 = "world";
const result2 = regexp.exec(str2);
console.log(result2);
6.5 (?:pattern) #
- (?:pattern) 是一个非捕获组(Non-capturing group)
- 。通常情况下,当你使用小括号 () 包裹一个表达式时,正则表达式会将匹配到的内容保存在一个捕获组中,方便后续的处理和引用。但是在某些场景下,我们并不想保存这些匹配内容,这时就可以使用非捕获组来达到这个目的
- 使用非捕获组可以减少内存的使用,并且提高正则表达式的性能。因此,在你并不需要在正则表达式中保留某个子表达式的匹配结果时,建议使用非捕获组来代替普通的捕获组
const str = 'hello123';
const regexp = /[a-z]+(?:\d+)/;
console.log(str.match(regexp));
6.6 (?...) #
- (?...) 是一种命名捕获组(Named Capturing Group)。它允许给一个子表达式指定一个名称,以便后续通过名称来引用该捕获组的匹配结果
- 命名捕获组的语法是 (?...),其中 name 是捕获组的名称,... 是要捕获的子表达式
const str = '2023-05-11';
const regexp = /(?<year>\d{4})-(?<month>\d{2})-(?<day>\d{2})/;
const match = str.match(regexp);
console.log(match.groups.year);
console.log(match.groups.month);
console.log(match.groups.day);
6.7 正向肯定断言 #
- (?=pattern) 是一个正向肯定断言(Positive Lookahead)
- 它表示匹配一个位置,该位置后面紧跟着的字符串匹配
pattern
- 但是这个位置本身不会被包含在匹配结果中,也就是说,它只是一个断言,不会捕获任何字符
const str = 'a1b2c3';
const regexp = /[a-z](?=\d)/g;
console.log(str.match(regexp));
6.8 正向否定断言 #
- (?!pattern) 是一个正向否定断言(Negative Lookahead)
- 它表示匹配一个位置,该位置后面紧跟着的字符串不匹配 pattern。但是,这个位置本身不会被包含在匹配结果中,也就是说,它只是一个断言,不会捕获任何字符
const str = 'a1b2c3';
const regexp = /\d(?!\d)/g;
console.log(str.match(regexp));
6.9 反向引用 #
- 反向引用是指使用 \n (n 为数字)来引用前面捕获的子表达式的匹配结果
- 如果在正则表达式中使用小括号 () 来包裹一个子表达式,那么该子表达式的匹配结果就会被保存在一个编号为 n 的捕获组中,其中 n 从左到右逐个增加
- 在这个表达式中,\b(\w+)\b 匹配一个单词,其中单词被保存在编号为 1 的捕获组中
const str = '<div>str</div>';
const regexp = /<(\w+)>.*?<\/\1>/g;
console.log(str.match(regexp)))
6.10 反向肯定断言 #
(?<=pattern) 是一个反向肯定断言(Positive Lookbehind)- 它表示匹配一个位置,该位置前面紧跟着的字符串匹配 pattern。但是,这个位置本身不会被包含在匹配结果中,也就是说,它只是一个断言,不会捕获任何字符
const str = '123abc';
const regexp = /(?<=\d)[a-z]/g;
console.log(str.match(regexp));
6.11 反向否定断言 #
(?<!pattern) 是一个反向否定断言(Negative Lookbehind)- 它表示匹配一个位置,该位置前面紧跟着的字符串不匹配 pattern。但是,这个位置本身不会被包含在匹配结果中,也就是说,它只是一个断言,不会捕获任何字符
const str = 'a1b2c3';
const regexp = /(?<!\d)[a-z]/g;
console.log(str.match(regexp));
7.字符串方法 #
7.1 match #
- 字符串的
match 方法和正则表达式对象的 exec 方法都是用于在字符串中查找与正则表达式匹配的内容
match 方法是字符串对象上的方法,正则表达式作为参数传递;exec 是正则表达式对象上的方法,字符串作为参数传递
7.1.1 非全局匹配 #
let regex = /to/;
let str = "string to search";
let matchResult = str.match(regex);
console.log(matchResult);
let execResult = regex.exec(str);
console.log(execResult);
7.1.2 全局匹配 #
- 当找不到匹配时,match 方法返回 null,而 exec 方法也返回 null
- 在全局匹配(g 标志)的情况下,match 方法返回所有匹配项的数组,而 exec 方法在每次调用时返回一个匹配项,需要多次调用以获得所有匹配项
exec 方法提供了更多关于匹配项的信息,如匹配项在字符串中的索引和捕获组- 尽管
match 方法在非全局模式下也提供这些信息,但在全局模式下,它只返回匹配项的数组,而不包含索引或捕获组信息
- 正则表达式对象具有 lastIndex 属性,用于存储上次匹配的位置。在使用带有 g 标志的正则表达式时,exec 方法从 lastIndex 开始搜索,并在找到匹配项后更新它。这使得在循环中多次调用 exec 可以找到所有匹配项。字符串的 match 方法不会使用或更改 lastIndex 属性
let regex = /apple/g;
let str = "apple to apple";
let matchResult = str.match(regex);
console.log(matchResult);
console.log(regex.lastIndex);
let execResult1 = regex.exec(str);
console.log(regex.lastIndex);
console.log(execResult1);
let execResult2 = regex.exec(str);
console.log(regex.lastIndex);
console.log(execResult2);
7.2 replace #
- 正则对象的 replace() 方法用于在字符串中替换与正则表达式匹配的部分
- regexp|substr:可以是一个正则表达式或者是一个要被替换的字符串。
- newSubstr|function:可以是一个新的字符串或者一个回调函数,用于生成替换后的内容
- replace() 方法并不会修改原始字符串,而是返回一个新的字符串作为替换后的结果。如果想要修改原始字符串,可以将返回值赋值给相应的变量
str.replace(regexp|substr, newSubstr|function)
const str = 'hello world';
const replaced = str.replace(/hello/g, 'hi');
console.log(replaced);
const name = 'zhang san';
const replacedName = name.replace(/(\w+)\s(\w+)/, '$2 $1');
console.log(replacedName);
const result = 'background-color'.replace(/-([a-z])/g, function (match, letter) {
return letter.toUpperCase();
});
console.log(result);
String.prototype.replace = function (pattern, replacement) {
let match;
let result = '';
let lastIndex = 0;
while ((match = pattern.exec(this)) !== null) {
result += this.slice(lastIndex, match.index);
if (typeof replacement === 'string') {
let replaced = replacement.replace(/\$(\d+)/g, function (_, group1) {
return match[parseInt(group1)];
});
result += replaced;
} else if (typeof replacement === 'function') {
result += replacement.apply(null, match);
}
lastIndex = pattern.lastIndex;
}
result += this.slice(lastIndex);
return result;
};
const result = 'background-color'.replace(/-([a-z])/g, function (match, letter) {
return letter.toUpperCase();
});
console.log(result);
const result2 = 'hello world'.replace(/(\w+) (\w+)/g, "$2 $1");
console.log(result2);
7.3 search #
- 字符串的 search() 方法用于在字符串中搜索指定的子字符串或正则表达式,并返回第一个匹配的索引位置
- regexp:可以是一个普通的字符串或一个正则表达式
str.search(regexp)
const str = 'hello world!';
const index = str.search(/world/i);
console.log(index);
7.4 split #
- 字符串的 split() 方法用于将字符串分割成字符串数组,基于指定的分隔符或正则表达式
- 当 separator 是一个字符串时,split() 方法会将字符串根据指定的字符串作为分隔符进行分割,并返回一个字符串数组
- separator:可以是一个字符串或正则表达式,用于指定分隔符
- limit(可选):用于限制返回的数组的长度
str.split(separator, limit)
const str = 'aaa bbb ccc';
console.log(str.split(/\s+/, 2));
const str = 'aaa bbb ccc;ddd,eee:fff';
console.log(str.split(/\W+/));
const str = 'aaa bbb ccc;ddd,eee:fff';
console.log(str.split(/(?:\s;,:)+/));
7.5 trim #
- 字符串的 trim() 方法用于去除字符串两端的空白字符(包括空格、制表符、换行符等)
- ^\s+:以一个或多个空白字符开头的模式
- \s+$:以一个或多个空白字符结尾的模式
const str = ' Hello, World! ';
const trimmed = str.trim();
console.log(trimmed);
function trim(str) {
return str.replace(/^\s+|\s+$/g, '');
}
const str = ' Hello, World! ';
const trimmed = trim(str);
console.log(trimmed);
8. 正则案例 #
8.1 验证网址 #
- 验证一个字符串是否以
http://或https://开头
function isValidUrl(str) {
const regex = /^(https?:\/\/)/;
return regex.test(str);
}
console.log(isValidUrl('http://www.baidu.com'));
console.log(isValidUrl('https://www.baidu.com'));
console.log(isValidUrl('httpss://www.baidu.com'));
console.log(isValidUrl('htt://www.baidu.com'));
console.log(isValidUrl('www.baidu.com'));
8.2 验证手机号 #
function isValidChinesePhoneNumber(str) {
const regex = /^(?:\+86)?1[3-9]\d{9}$/;
return regex.test(str);
}
const phone1 = "13012345678";
const phone2 = "+8618123456789";
const phone3 = "12012345678";
const phone4 = "1312345678";
console.log(isValidChinesePhoneNumber(phone1));
console.log(isValidChinesePhoneNumber(phone2));
console.log(isValidChinesePhoneNumber(phone3));
console.log(isValidChinesePhoneNumber(phone4));
8.3 验证身份证 #
8.3.1 简版 #
- 前 6 位:表示行政区划代码,即表示持证人所在地的省、市、县(区)的行政区划代码
- 接下来的 8 位:表示出生日期,格式为 YYYYMMDD,如 19900101,如果是15位的身份证号的话只包含年份的后两位数字
- 再接下来的 3 位:表示顺序码。顺序码用于区分同一地区、同一出生日期的不同个体。其中,奇数分配给男性,偶数分配给女性。例如,同一地区同一天出生的男性可能分别获得 001、003、005 等顺序码,而女性可能获得 002、004、006 等顺序码
- 最后 1 位:表示校验位。校验位是通过前 17 位数字按照一定的计算规则计算出来的,用于检查身份证号码是否有效。校验位可以是 0-9 的数字或字母 "X"(或 "x"),如果是15位的身份证号的话没有校验位
function isValidChineseID(str) {
const regex = /^\d{6}\d{6,8}\d{3}[\dXx]?$/;
return regex.test(str);
}
const id1 = "11010119900307123X";
const id2 = "11010119900307123x";
const id3 = "110101199003071234";
const id4 = "110101900307123";
console.log(isValidChineseID(id1));
console.log(isValidChineseID(id2));
console.log(isValidChineseID(id3));
console.log(isValidChineseID(id4));
8.3.2 专业版 #
8.3.2.1 身份证号 #
- 15 位身份证号码部分:^(\d{6})(\d{2}((0[1-9])|(1[0-2]))(([0|1|2]\d)|3[0-1]))\d{3}$
- \d{6}:匹配 6 位行政区划代码
- \d{2}((0[1-9])|(1[0-2]))(([0|1|2]\d)|3[0-1]):匹配 6 位出生日期 YYMMDD
- \d{3}:匹配 3 位顺序码
- 18 位身份证号码部分:^(\d{6})(19|20)\d{2}((0[1-9])|(1[0-2]))(([0|1|2]\d)|3[0-1])\d{3}(\d|X)$
- \d{6}:匹配 6 位行政区划代码
- (19|20)\d{2}((0[1-9])|(1[0-2]))(([0|1|2]\d)|3[0-1]):匹配 8 位出生日期 YYYYMMDD
- \d{3}:匹配 3 位顺序码
- (\d|X):匹配校验位,可以是数字或 "X"
8.3.2.2 校验位 #
- 1.将前 17 位数字分别乘以对应的权重系数:
[7, 9, 10, 5, 8, 4, 2, 1, 6, 3, 7, 9, 10, 5, 8, 4, 2],然后将所有乘积相加,得到一个总和
- 2.将总和对 11 取模,得到一个余数
- 3.将余数映射到校验位字符。余数可以是 0-10,它们分别映射到字符:
[1, 0, X, 9, 8, 7, 6, 5, 4, 3, 2]
8.3.2.3 代码 #
function isValidChineseID(id) {
const idPattern = /^(\d{6})(\d{2}((0[1-9])|(1[0-2]))(([0|1|2]\d)|3[0-1]))\d{3}$|^(\d{6})(19|20)\d{2}((0[1-9])|(1[0-2]))(([0|1|2]\d)|3[0-1])\d{3}(\d|X)$/i;
const matched = idPattern.test(id);
if (!matched) return false;
if (id.length === 15) return true;
const checkDigit = calculateCheckDigit(id);
return checkDigit === id[17].toUpperCase();
}
console.log(isValidChineseID("110101900307123"));
console.log(isValidChineseID("450481197804234431"));
console.log(isValidChineseID("123456789012345"));
function calculateCheckDigit(id) {
const weights = [7, 9, 10, 5, 8, 4, 2, 1, 6, 3, 7, 9, 10, 5, 8, 4, 2];
const checkDigits = ['1', '0', 'X', '9', '8', '7', '6', '5', '4', '3', '2'];
let sum = 0;
for (let i = 0; i < 17; i++) {
sum += parseInt(id[i]) * weights[i];
}
const remainder = sum % 11;
return checkDigits[remainder];
}
8.4 验证中文姓名 #
- Unicode 是一种字符集编码标准,它为世界上的各种文字系统分配唯一的数字表示,使计算机能够处理各种语言的文本
- 基本汉字:[\u4e00-\u9fa5]这个范围包含了 20,971 个基本汉字,涵盖了简体和繁体汉字
function isValidChineseName(name) {
const namePattern = /^[\u4e00-\u9fa5]+(\.[\u4e00-\u9fa5]+)*$/;
return namePattern.test(name);
}
console.log(isValidChineseName("张三"));
console.log(isValidChineseName("马克.吐温"));
console.log(isValidChineseName("马克.吐温.吐司"));
console.log(isValidChineseName("John"));
8.5 验证用户名 #
- 验证内容为数字、字母、下划线,长度为6到16位
- \w 是一个预定义的字符类,匹配任何字母、数字和下划线
function isValidString(str) {
const regexp = /^[a-zA-Z0-9_]{6,16}$/;
const regexp = /^\w{6,16}$/;
return regexp.test(str);
}
console.log(isValidString("abc123_"));
console.log(isValidString("abc!123"));
console.log(isValidString("abc"));
8.6 13-65 #
- ^:表示匹配字符串的开始
- (1[3-9]|[2-5]\d|6[0-5]):表示匹配一个满足以下条件的数字:
- 1[3-9]:以 1 开头,第二位是 3 到 9 之间的数字(即 13 到 19)
- [2-5]\d:以 2 到 5 开头,第二位是任意数字(即 20 到 59)
- 6[0-5]:以 6 开头,第二位是 0 到 5 之间的数字(即 60 到 65)
- $:表示匹配字符串的结尾
function isValidNumber(str) {
const regexp = /^(1[3-9]|[2-5]\d|6[0-5])$/;
return regexp.test(str);
}
console.log(isValidNumber('3'));
console.log(isValidNumber('13'));
console.log(isValidNumber('23'));
console.log(isValidNumber('33'));
console.log(isValidNumber('43'));
console.log(isValidNumber('53'));
console.log(isValidNumber('63'));
console.log(isValidNumber('73'));
console.log(isValidNumber("66"));
8.7 验证邮箱 #
function isValidEmail(email) {
return /\w+@(\w+\.)+[a-z]{2,}/.test(email)
}
console.log(isValidEmail("zhang@qq.com"));
console.log(isValidEmail("zhang@126.com.cn"));
8.8 首字母大写 #
let str = 'good Good studY, Day a up';
let result = str.replace(/\b(\w)(\w*)\b/g,function(matched,group1,group2){
return group1.toUpperCase()+group2.toLowerCase();
});
console.log(result);
8.9 最多字母 #
let str = 'abbcccdddccc';
let result =
[...str]
.sort()
.join('')
.match(/([a-z])\1*/g)
.sort((a,b)=>a.length-b.length)
.pop();
console.log(`${result[0]}出现了${result.length}`);
let charsCount = {}
for (let c of str){
if(typeof charsCount[c] === 'undefined'){
charsCount[c]=1;
}else{
charsCount[c]+=1;
}
}
const entries = Object.entries(charsCount);
let maxEntry=null;
for(let entry of entries){
if(maxEntry){
if(entry[1] > maxEntry[1]){
maxEntry=entry;
}
}else{
maxEntry=entry;
}
}
8.10 千分符 #
- 匹配所有不在数字边界处,且后面跟着一组三位数字的位置,同时这组数字是字符串的结尾。这样,在这些位置上进行替换操作可以实现千分符的效果
- \B:这是一个特殊的元字符,表示匹配一个非单词边界,即非单词字符(例如空格、标点符号等)。在这个正则中使用 \B 是为了匹配数字之间的位置,而不是数字与单词之间的位置
- (?=(\d{3})+$):这是一个正向肯定预查,用于匹配后面满足特定条件的位置。在这里,它的作用是匹配后面跟着一组三位数字的位置,并且这组数字是字符串的结尾($ 表示结尾)
- \d{3}:这是一个简单的模式,匹配连续的三个数字
- (\d{3})+:这是一个捕获组,用于捕获连续的三位数字的组合。(\d{3}) 表示匹配三个数字并将其捕获,然后 + 表示可以匹配多个连续的三位数字
String.prototype.withThousandsSeparator = function () {
return this.replace(/\d{1,3}(?=(\d{3})+$)/g, (matched) => {
return matched + ',';
});
}
let str = '123456789';
console.log(str.withThousandsSeparator());
8.11 格式化时间 #
String.prototype.format = function(inputFormat,outputFormat){
const timeParts = [];
const regexpSource = inputFormat.replace(/(YYYY|MM|DD|hh|mm|ss)/g,(matched)=>{
timeParts.push(matched);
return matched==='YYYY'?'(\\d{4})':'(\\d{2})';
});
let regexp = new RegExp(regexpSource);
const resultArray = this.match(regexp);
let groups = resultArray.slice(1);
const dateValues = timeParts.reduce((memo,part,index)=>{
memo[part]=groups[index];
return memo;
},{});
return outputFormat.replace(/(YYYY|MM|DD|hh|mm|ss)/g,(matched)=>dateValues[matched]);
}
let dateStr = '2023#23#05 12@13@15';
let result = dateStr.format(
'YYYY#DD#MM hh@mm@ss',
'YYYY-MM-DD hh:mm:ss'
);
console.log(result);
8.12 URL #
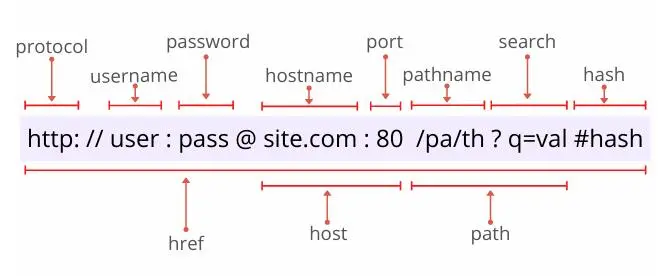
- URL(Uniform Resource Locator)是互联网上的一种资源的简洁标识。它是一种特定格式的字符串,可以指向互联网上的任何资源。
- 以下是一个URL的完整示例:http://username:password@www.example.com:80/path/to/myfile.html?key1=value1&key2=value2#SomewhereInTheDocument
- 这个URL的各个部分具有以下含义:
- http: 这部分被称为协议或者方案。它定义了如何访问和互动资源。常见的协议有HTTP, HTTPS, FTP, FILE等。
- username:password 这是可选部分,用于需要身份验证的服务。
- www.example.com 这部分被称为主机名或者域名。它定义了我们想要访问的服务器的地址。这可以是一个IP地址或者一个注册的域名。
- :80 这部分是可选的,称为端口号。它定义了服务器上的哪个服务我们要访问。如果未指定,那么默认端口是协议的标准端口(例如,对于HTTP是80,HTTPS是443)。
- /path/to/myfile.html 这部分是路径,它指定了服务器上的哪个具体资源我们想要访问。
- ?key1=value1&key2=value2 这部分是查询字符串,用于发送参数到服务器。它以问号开始,参数以键值对的形式存在,并用&符号分隔。
- #SomewhereInTheDocument 这部分被称为片段或者锚点,它指定了网页中的一个位置。当你访问一个URL时,浏览器会尝试滚动到这个位置。
let url = `http://username:password@www.baidu.com:80/path/to/myfile.html?key1=value1&key2=value2#SomewhereInTheDocument`;
function parseUrl(url,parseQuery=false){
let pattern = /^(https?):\/\/([^:]+):([^@]+)@([^:]+):(\d+)([^?]+)\?([^#]+)#(.+)/;
let result = url.match(pattern);
const [,protocal,username,password,hostname,port,pathname,query,hash] = result;
let parseResult= {
protocal,username,password,hostname,port,pathname,query,hash
}
parseResult.host=hostname+":"+port;
parseResult.path = pathname+'?'+query;
if(parseQuery){
let queryObj = {};
parseResult.query.replace(/([^=&]+)=([^=&]+)/g,function(matched,key,value){
queryObj[key]=value;
});
parseResult.query =queryObj;
}
return parseResult
}
let result = parseUrl(url,true);
console.log(result);
function parseUrl(url,parseQuery=false){
let pattern = /(?<protocal>https?|ftp|file):\/\/((?<username>[^:]+):(?<password>[^@]+)@)?(?<hostname>[^:\s?]+)(:(?<port>\d+))?(?<pathname>[^?\s]+)?(?<query>\?[^#]+)?(?<hash>#.+)?/;
let result = url.match(pattern);
const {protocal,username='',password='',hostname,port=80,pathname='/',query='',hash=''} = result.groups;
let parsedResult = {
protocal,
username,
password,
hostname,
port,
pathname,
query,
hash
}
if(parseQuery){
let queryObj = {};
query.slice(1).replace(/([^=&]+)=([^=&]+)/g,function(_,key,value){
queryObj[key]=value;
});
parsedResult.query = queryObj;
}
return parsedResult;
}
let url1 = 'http://localhost?name=zhufeng&age=16';
let result = parseUrl(url1,true);
console.log(result);
附录 #
RegExp静态属性 #
| 属性/方法名 |
描述与作用 |
| RegExp.input |
静态属性,代表默认的当前正在匹配的输入字符串 |
| RegExp.lastIndex |
静态属性,代表默认的下一次匹配开始的索引位置 |
| RegExp.$1-$9 |
静态属性,代表匹配到的第1至9个子表达式的内容 |
| RegExp.$_ |
静态属性,代表默认的当前正在匹配的输入字符串 |
| RegExp.leftContext |
静态属性,代表当前匹配结果左侧的文本 |
| RegExp.rightContext |
静态属性,代表当前匹配结果右侧的文本 |
| RegExp.$& |
静态属性,代表当前匹配结果的文本 |
| RegExp.$` |
静态属性,代表当前匹配结果左侧的文本 |
| RegExp.$' |
静态属性,代表当前匹配结果右侧的文本 |
| RegExp.$+ |
静态属性,代表匹配到的最后一个子表达式的内容 |
| RegExp.$* |
静态属性,代表匹配到的所有子表达式的内容 |
| RegExp.$_ |
静态属性,代表默认的当前正在匹配的输入字符串 |
| RegExp.$input |
静态属性,代表默认的当前正在匹配的输入字符串 |
| RegExp.$regexp |
静态属性,代表当前正则表达式对象的源代码 |
| RegExp.$1-$99 |
静态属性,代表匹配到的第1至99个子表达式的内容 |
| RegExp.$_ |
静态属性,代表默认的当前正在匹配的输入字符串 |
| RegExp.$& |
静态属性,代表当前匹配结果的文本 |
| RegExp.$+ |
静态属性,代表匹配到的最后一个子表达式的内容 |
| RegExp.$* |
静态属性,代表匹配到的所有子表达式的内容 |
| RegExp.$_ |
静态属性,代表默认的当前正在匹配的输入字符串 |
| RegExp.$` |
静态属性,代表当前匹配结果左侧的文本 |
| RegExp.$' |
静态属性,代表当前匹配结果右侧的文本 |
| RegExp.$1-$99 |
静态属性,代表匹配到的第1至99个子表达式的内容 |
| RegExp.$_ |
静态属性,代表默认的当前正在匹配的输入字符串 |
| RegExp.$& |
静态属性,代表当前匹配结果的文本 |
RegExp实例属性 #
| 属性/方法名 |
描述与作用 |
| source |
正则表达式的源代码 |
| global |
是否开启全局匹配模式 |
| ignoreCase |
是否忽略大小写 |
| multiline |
是否开启多行匹配模式 |
| lastIndex |
当前正则表达式匹配完成后,下一次匹配开始的索引位置 |
| exec(str) |
在一个字符串中执行匹配搜索,返回一个数组或 null |
| test(str) |
在一个字符串中测试是否存在匹配,返回 true 或 false |
| toString() |
返回表示 RegExp 对象的字符串 |
| toLocaleString() |
返回表示 RegExp 对象的本地化字符串 |
| valueOf() |
返回 RegExp 对象的原始值 |