1. 渲染页面 #
从输入URL地址到看到页面,中间经历了以下过程:
URL输入:在浏览器地址栏中输入URL。
DNS解析:浏览器查看缓存,如果没有找到相关记录,就会向网络发送一个DNS查询请求,来找到对应URL的IP地址。
TCP连接:浏览器使用IP地址和服务器建立TCP连接。这一步包括TCP的三次握手过程。
HTTP请求:浏览器通过TCP连接向服务器发送HTTP请求。请求包含了许多关于浏览器、用户以及请求内容的信息。
服务器处理请求并返回HTTP响应:服务器处理收到的请求,然后返回一个HTTP响应。响应通常包含了状态码、响应头和响应体。响应体就是我们通常所说的“网页内容”,比如HTML文件。
浏览器解析绘制页面
2. URL输入 #
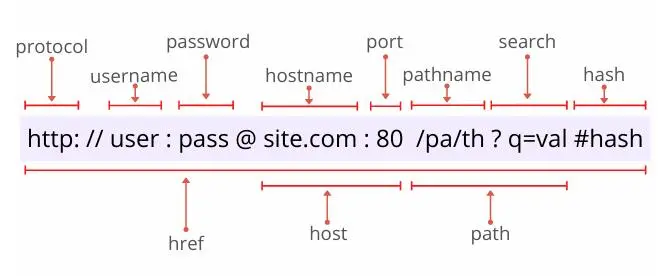
- URL(Uniform Resource Locator)是互联网上的一种资源的简洁标识。它是一种特定格式的字符串,可以指向互联网上的任何资源。
- 以下是一个URL的完整示例:http://username:password@www.example.com:80/path/to/myfile.html?key1=value1&key2=value2#SomewhereInTheDocument
- 这个URL的各个部分具有以下含义:
- http: 这部分被称为协议或者方案。它定义了如何访问和互动资源。常见的协议有HTTP, HTTPS, FTP, FILE等。
- username:password 这是可选部分,用于需要身份验证的服务。
- www.example.com 这部分被称为主机名或者域名。它定义了我们想要访问的服务器的地址。这可以是一个IP地址或者一个注册的域名。
- :80 这部分是可选的,称为端口号。它定义了服务器上的哪个服务我们要访问。如果未指定,那么默认端口是协议的标准端口(例如,对于HTTP是80,HTTPS是443)。
- /path/to/myfile.html 这部分是路径,它指定了服务器上的哪个具体资源我们想要访问。
- ?key1=value1&key2=value2 这部分是查询字符串,用于发送参数到服务器。它以问号开始,参数以键值对的形式存在,并用&符号分隔。
- #SomewhereInTheDocument 这部分被称为片段或者锚点,它指定了网页中的一个位置。当你访问一个URL时,浏览器会尝试滚动到这个位置。
3. DNS解析 #
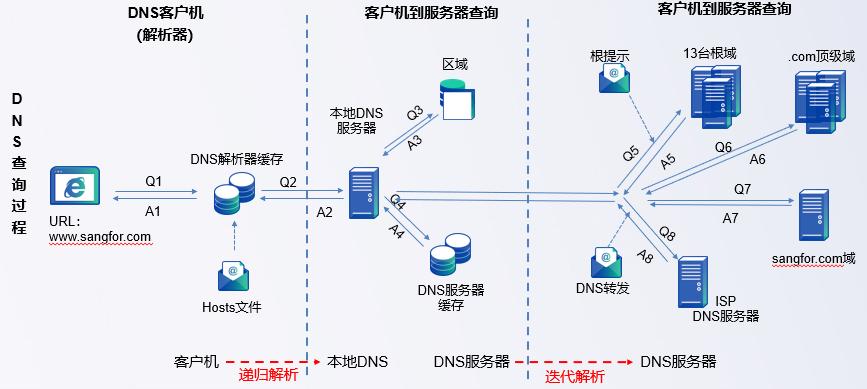
DNS (域名系统) 解析是将易于人类理解的域名转换为计算机能理解的 IP 地址的过程。在浏览器中输入 URL 地址并请求网页时,这个过程是必要的,因为计算机网络只能通过 IP 地址在互联网上查找和定位设备。以下是 DNS 解析的基本步骤:
浏览器缓存查询:浏览器首先检查其缓存中是否有要访问的域名对应的 IP 地址。如果找到了,则直接使用这个 IP 地址进行访问。
操作系统缓存查询:如果浏览器缓存中没有找到,则查询操作系统的 DNS 缓存。这是因为所有通过 DNS 解析得到的 IP 地址,操作系统都会存储在自己的 DNS 缓存中。
路由器缓存查询:如果在操作系统的缓存中还是没有找到,则查询路由器的 DNS 缓存。这是因为路由器也可能会缓存 DNS 记录。
ISP DNS 服务器查询:如果在路由器缓存中仍未找到,则查询 ISP(Internet Service Provider,互联网服务提供商)的 DNS 服务器。ISP 的 DNS 服务器中有许多 DNS 记录,可能会有你需要的记录。
递归查询:如果 ISP 的 DNS 服务器中也没有你需要的 DNS 记录,那么这个 DNS 服务器就会作为客户端向其他 DNS 服务器发起查询。这个过程可能涉及到根服务器、顶级域服务器和权威服务器。
根服务器:这些服务器知道顶级域 DNS 服务器的 IP 地址(如 .com, .org, .net等)。
- 顶级域(TLD)服务器:这些服务器知道如何找到特定的二级域(例如,.google.com 或 .amazon.com)的服务器。
权威 DNS 服务器:这是一个提供完全正确 DNS 信息的服务器。权威服务器会返回请求的 IP 地址给 ISP 的 DNS 服务器。
DNS 记录返回给客户端:ISP 的 DNS 服务器将从权威服务器获得的 DNS 记录返回给客户端(这里是浏览器),并将 DNS 记录存储在它的缓存中以备将来使用。
浏览器请求 IP 地址:浏览器接收到 IP 地址后,它将请求该 IP 地址,并将返回的网站内容显示给用户。
4.TCP连接 #
4.1 报文段 #
在网络通信中,特别是在使用TCP(Transmission Control Protocol,传输控制协议)时,我们通常会听到“报文段”这个术语。
在TCP协议中,数据不是一次性完整发送的,而是被划分为一个个较小的数据块进行发送,这样做是为了更有效地利用网络资源,以及方便错误检测和恢复。每一个这样的数据块,加上TCP头部信息(比如序列号、确认号、标志位等),就构成了一个TCP报文段。
在TCP的通信过程中,报文段是数据传输的基本单位。发送方将数据封装成报文段后通过网络发送,接收方收到报文段后进行解析,获取头部信息和实际数据。这是TCP实现可靠数据传输的基础。
4.2 标志位 #
在TCP(Transmission Control Protocol,传输控制协议)中,SYN(Synchronize Sequence Numbers,同步序列编号)、ACK(Acknowledgment,确认)和FIN(Finish,结束)是三种重要的标志位,用于控制TCP连接的建立、数据传输和连接终止。
1. SYN(Synchronize):在TCP三次握手过程中,当客户端尝试建立一个新的连接时,它会设置SYN标志位并发送一个TCP报文段给服务器。SYN标志位设为1表示这是一个连接请求或连接接受报文,同时会携带一个初始的序列号。服务器在回应客户端请求时,也会设置SYN标志位,并提供自己的序列号。(TCP规定SYN被设置为1的报文段不能写携带数据,但要消耗掉一个序号)
2. ACK(Acknowledgment):ACK标志位在TCP报文段中表示该报文包含的确认号是有效的。当接收方收到数据后,为了告知发送方数据已成功接收,接收方会发送一个设置了ACK标志位的TCP报文,其中的确认号通常设为已接收到的数据的序列号+1。如果发送方在一定时间内没有收到ACK确认报文,那么它会重发对应的数据。
3. FIN(Finish):在TCP四次挥手过程中,当一方完成了数据传输并想要关闭连接时,会设置FIN标志位并发送一个TCP报文给对方。FIN标志位设为1表示该方已经没有数据要发送了,请求关闭连接。对方在收到FIN报文后,会发送一个ACK报文来确认接收到了连接关闭的请求。
这三种标志位都是TCP协议为了提供可靠的、基于连接的数据传输服务而设计的重要工具。通过它们的工作,TCP可以在不可靠的IP网络上提供一种可靠的传输服务。
4.3 序列号 #
在TCP(Transmission Control Protocol,传输控制协议)中,序列号(Sequence Number,简称Seq)有着至关重要的作用,主要用于以下两个目的:
1. 确定数据顺序:TCP是一个面向字节流的协议,当发送大量数据时,TCP会将数据分割成许多小的数据包(称为TCP报文段)进行发送。每一个报文段在发送时都会被赋予一个序列号,这个序列号指示了该报文段中的第一个字节在整个数据流中的位置。这样,当接收方收到这些报文段后,即使它们的到达顺序与发送顺序不一致,也能通过查看每个报文段的序列号,将这些报文段按正确的顺序重新组合成原始的数据流。
2. 确认数据接收:除了确定数据顺序外,序列号还用于确认数据的接收。当接收方收到一个报文段后,它会返回一个确认报文(ACK),其中的确认号(Acknowledgment Number)就是期望下一个接收到的报文段的第一个字节的序列号,也就是已收到的最后一个字节的序列号+1。这样,发送方就能知道哪些数据已经被接收,哪些还没有。
因此,TCP的序列号是实现数据的有序、可靠传输的关键。
4.4 三次握手 #
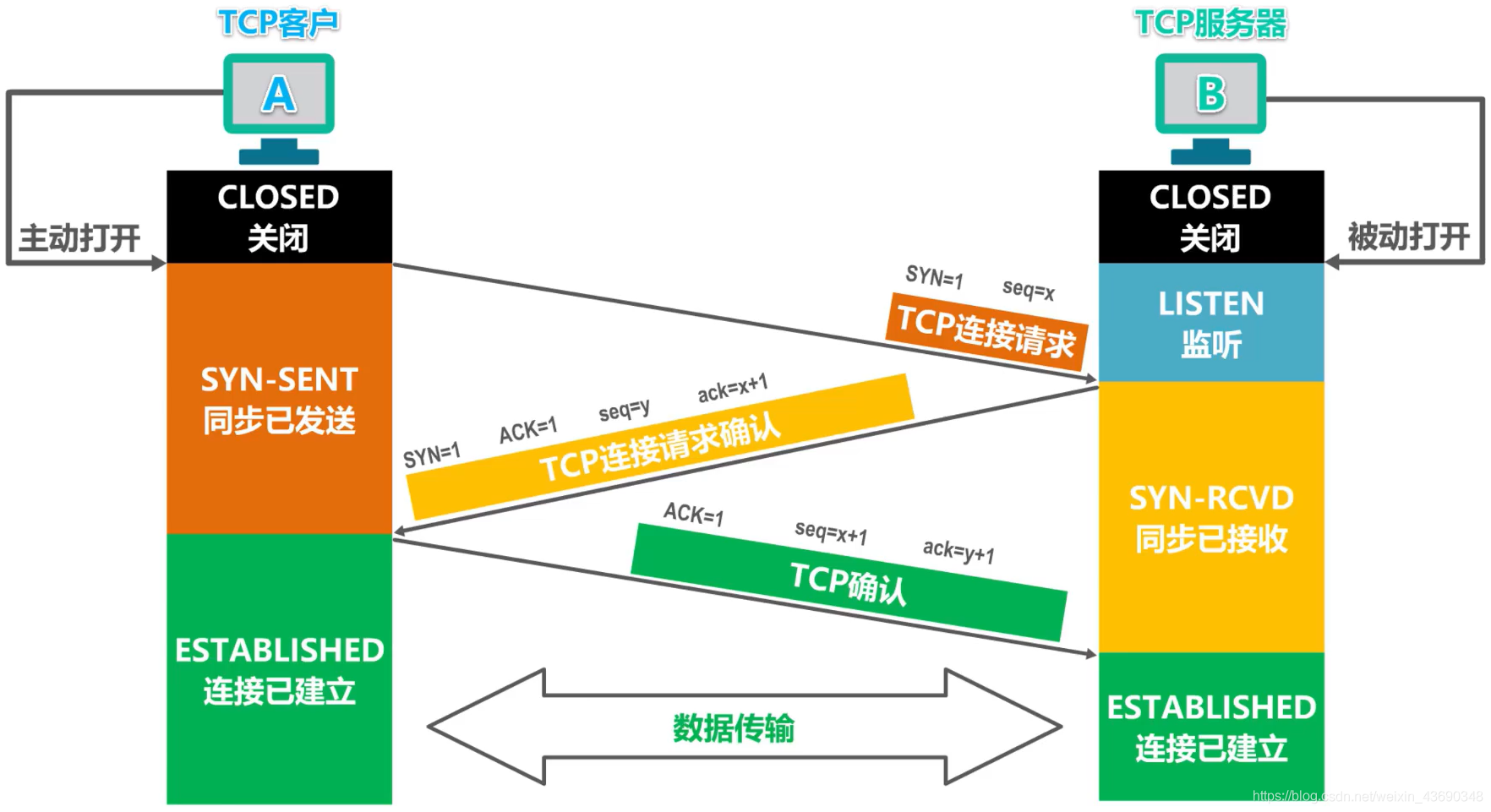
TCP(Transmission Control Protocol,传输控制协议)是一种可靠的,面向连接的网络通信协议。在TCP协议中,通信双方在发送数据之前需要建立连接,这个过程被称为“三次握手”(Three-Way Handshake)。
以下是三次握手的过程:
SYN:首先,客户端发送一个TCP报文段,其中SYN标志位设为1,同时指定一个初始序列号x(通常是随机生成的),然后等待服务器的回应。这个阶段完成了“同步”请求,即请求建立连接。
SYN-ACK:服务器接收到客户端的SYN报文段后,如果同意建立连接,会发送一个SYN-ACK报文段作为回应。这个报文段中,SYN标志位和ACK标志位都设为1,确认号设置为x+1,同时也会指定一个自己的初始序列号y。
ACK:客户端接收到服务器的SYN-ACK报文段后,会再发送一个ACK报文段。在这个报文段中,ACK标志位设为1,序列号设为x+1,确认号设为y+1。当服务器接收到这个ACK报文段后,连接就正式建立,双方可以开始传输数据。
通过这个三次握手的过程,通信双方可以互相确认对方的接收、发送能力,确保数据传输的可靠性。同时,三次握手也能防止已经失效的连接请求报文突然传到服务器,产生错误。
4.5 四次挥手 #
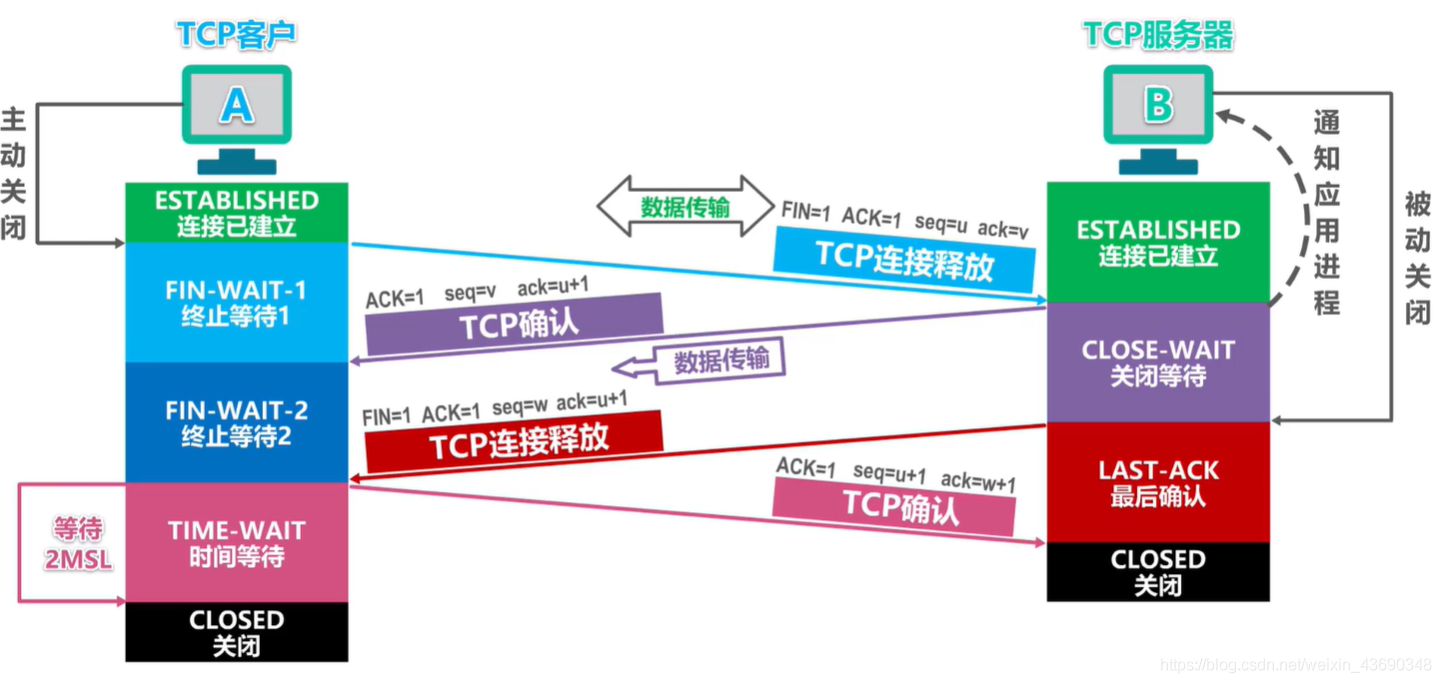
TCP(Transmission Control Protocol,传输控制协议)在结束一个已建立的连接时,使用了一个被称为"四次挥手"(Four-Way Handshake)的过程。这个过程确保了双方都能结束连接。
以下是四次挥手的过程:
FIN:首先,当主动关闭连接的一方(假设是客户端)完成数据传输后,它会发送一个FIN(Finish)报文段给对方,表示自己已经没有数据要发送了,希望关闭连接。这个FIN报文段中,FIN标志位设为1,同时指定一个序列号。
ACK:接收到FIN报文段的对方(在这里是服务器),会发送一个ACK(Acknowledgment)报文段作为回应,表示已经收到了关闭连接的请求,但可能还有数据需要发送。在这个ACK报文段中,ACK标志位设为1,确认号为收到的序列号加1。
FIN:当服务器发送完所有需要发送的数据后,它也会发送一个FIN报文段,表示已经准备好关闭连接。
ACK:客户端接收到服务器的FIN报文段后,还需要再回应一个ACK报文段,然后等待一段时间(约2倍的最大报文段生存时间)再真正关闭连接。这是为了防止服务器未收到最后的ACK报文段而重发FIN报文段。
这就是四次挥手的过程。和三次握手一样,这个过程也是为了保证连接的可靠性。值得注意的是,TCP是全双工协议,所以每个方向都必须单独进行关闭。这是为什么需要四次挥手,而不是两次挥手的原因。
5.HTTP请求 #
5.1. HTTP #
- HTTP请求和响应模型描述的是客户端和服务器之间如何进行HTTP通信的过程。这个过程基于请求/响应模型,即客户端发起请求,服务器响应请求。
- 以下是一个简单的HTTP请求和响应模型的流程:
- 客户端发起请求:客户端(通常是浏览器,但也可以是任何可以发送HTTP请求的应用)生成一个HTTP请求消息并发送给服务器。这个请求消息包括请求行(包括HTTP方法,请求的URL,和HTTP版本),请求头(包含了如User-Agent,Accept,Cookie等一些元数据),以及可选的请求体(如POST或PUT请求中的数据)
- 服务器处理请求:服务器接收到HTTP请求消息后,解析请求行,请求头和请求体,然后进行相应的处理,这可能包括查询数据库,执行计算,或者调用其他服务
- 服务器发送响应:服务器处理完请求后,会生成一个HTTP响应消息并发送回客户端。这个响应消息包括响应行(包括HTTP版本,状态码,和原因短语),响应头(包含了如Content-Type,Set-Cookie等一些元数据),以及可选的响应体(如请求的资源,错误消息等)
- 客户端处理响应:客户端接收到HTTP响应消息后,解析响应行,响应头和响应体,然后进行相应的处理,这可能包括显示HTML页面,处理JSON数据,或者处理错误消息
5.2 请求 #
5.2.1 请求行 #
- HTTP请求行是HTTP请求的第一部分,它指定了要执行的请求类型(也称为方法),资源的标识符(URL),以及HTTP的版本
- 它通常位于HTTP请求消息的首行。以下是其格式:
<method> <request-URI> <version>
method:这是HTTP方法,例如GET,POST,PUT,DELETE等。这些方法定义了对请求的URI指定的资源进行何种操作GET:请求指定的页面信息,并返回实体主体。POST:向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST请求可能会导致新的资源的建立和/或已有资源的修改。PUT:从客户端向服务器传送的数据取代指定的文档的内容。DELETE:请求服务器删除指定的页面。
request-URI:这是请求的目标资源的标识符,通常是URL。version:这是客户端使用的HTTP协议的版本,常见的有HTTP/1.0和HTTP/1.1
5.2.2 请求头 #
- HTTP请求头是在HTTP请求中包含的一组键值对,它们提供了有关请求或请求客户端的信息
- 这些信息可能包括客户端(如浏览器)类型、接受的响应格式、发起请求的页面的来源等等
- 以下是一些常见的HTTP请求头:
| 请求头 | 描述 |
|---|---|
| Accept | 该头部告诉服务器,客户端可以处理的媒体类型,如text/html、application/json等。 |
| Content-Type | 该头部在POST和PUT请求中使用,告诉服务器请求体的媒体类型。常见的值包括application/x-www-form-urlencoded、multipart/form-data和application/json等。 |
| User-Agent | 该头部包含了关于发起请求的用户代理(通常是浏览器)的信息。 |
| Authorization | 该头部用于传递身份验证凭据。 |
| Cookie | 该头部携带了由服务器设置的cookie,服务器可以使用它们来识别和跟踪用户。 |
| Referer | 该头部指示发起请求的页面的URL,这可以帮助服务器了解哪些页面在链接到其资源。 |
| X-Requested-With | 这是一个自定义的HTTP头,最常用于识别Ajax请求。例如,某些框架(如jQuery)会自动添加X-Requested-With: XMLHttpRequest头。 |
5.2.3 请求体 #
- 请求体(Request Body)是HTTP请求中的一部分,通常用于POST和PUT方法中,用于向服务器发送要处理的数据
- 这些数据可能是用户在表单中填写的数据,也可能是JSON对象,或者其他格式的数据
- 请求体的格式取决于
Content-Type请求头的值 - 例如,如果"Content-Type"头的值为
application/x-www-form-urlencoded,那么请求体的数据格式应该如下:
name=zhufeng&age=18
- 如果
Content-Type头的值为application/json,那么请求体的数据格式应该如下:
{
"name": "zhufeng",
"age": 18
}
- 如果"Content-Type"头的值为"multipart/form-data",用于在HTTP请求中发送二进制数据,则通常用于上传文件
- 请求头指定了"Content-Type"为"multipart/form-data",并且定义了一个边界字符串"boundary"
- 请求体由几个部分组成,每个部分用边界字符串隔开
- 每个部分由一个或多个头部和一个主体组成
- "Content-Disposition"头指定了字段的名字,如果这个部分包含一个文件,它还会包含文件的名字
- "Content-Type"头是可选的,用于指定该部分主体的媒体类型
- 请求体的最后一个部分后面跟着一个带有两个连字符的边界字符串,表示请求体的结束
POST /upload HTTP/1.1
Host: localhost
Content-Type: multipart/form-data;boundary="boundary"
--boundary
Content-Disposition: form-data; name="field1"
value1
--boundary
Content-Disposition: form-data; name="field2"; filename="example.txt"
Content-Type: text/plain
Hello, World!
--boundary--
在HTTP GET请求中,通常没有请求体,因为GET请求用于获取资源,而不是发送数据。数据通常以查询参数(query parameters)的形式附加在URL中
5.3 响应 #
5.3.1 响应行 #
- 响应行(Status-Line)是HTTP响应消息的第一行,也是响应消息的一部分
- 它包含了三个部分:HTTP版本,状态码,以及原因短语
- HTTP版本:这表明了服务器使用的HTTP版本。典型的值包括 "HTTP/1.0" 和 "HTTP/1.1"。在最新的HTTP版本,HTTP/2中,这个值保持为"HTTP/1.1",因为HTTP/2的响应是以二进制格式,而不是文本格式发送的
- 状态码:这是一个三位数字的代码,它表明了请求的结果。状态码被分为几个类别,从100到500,每个类别都有特定的含义。例如,200系列的状态码表示请求已成功处理,400系列的状态码表示客户端错误,500系列的状态码表示服务器错误
- 原因短语:这是一个简短的描述,说明了状态码的含义。例如,状态码200的原因短语是 "OK",状态码404的原因短语是 "Not Found"
- 在下面这个例子中,HTTP版本是1.1,状态码是200,原因短语是 "OK"。这表明了请求已经被成功处理
HTTP/1.1 200 OK
状态码
- HTTP状态码是由三位数字组成,每个数字都有特定的含义
- 以下是HTTP状态码分类的总结:
| 状态码类别 | 描述 |
|---|---|
| 1xx | 信息响应:请求已收到,继续处理。 |
| 2xx | 成功:请求已被服务器接收、理解、并接受。 |
| 3xx | 重定向:需要进一步的操作以完成请求。通常这些状态码用于URI已经改变的情况。 |
| 4xx | 客户端错误:请求包含语法错误或无法完成请求。通常这些状态码用于服务器无法完成明显无效的请求。 |
| 5xx | 服务器错误:服务器在处理请求的过程中发生错误。通常这些状态码用于所有其他错误情况。 |
- 以下是常见的HTTP状态码:
| 状态码 | 名称 | 描述 |
|---|---|---|
| 200 | OK | 请求成功。这通常是对成功GET和PUT请求的响应。 |
| 201 | Created | 请求成功,并创建了新的资源,通常是对POST请求的响应。 |
| 204 | No Content | 请求成功,但没有要返回的表示,通常用于DELETE和PUT请求。 |
| 301 | Moved Permanently | 被请求的资源已永久移动到新位置,并提供了新的URL。 |
| 302 | Found | 被请求的资源临时从不同的URI响应请求。 |
| 400 | Bad Request | 请求无法被服务器理解,由于客户端语法错误。 |
| 401 | Unauthorized | 请求需要用户验证。 |
| 403 | Forbidden | 服务器理解请求,但是拒绝执行它。 |
| 404 | Not Found | 请求的资源在服务器上没有找到。 |
| 500 | Internal Server Error | 服务器遇到了一个未知的错误。 |
| 503 | Service Unavailable | 服务器暂时无法处理请求,通常这是因为过载或维护。 |
5.3.2 响应头 #
- HTTP响应头包含了服务器对请求的响应信息,比如资源的元数据或者关于服务器本身的信息
- 响应头可以为客户端(如浏览器)提供一些额外的上下文信息,以帮助其正确解析和处理响应
- 下面是一些常见的HTTP响应头:
| 响应头 | 描述 |
|---|---|
| Content-Type | 指定了响应体的媒体类型,如 text/html、application/json等。 |
| Content-Length | 指定了响应体的字节数。这可以让客户端知道何时读取完整的响应体。 |
| Set-Cookie | 用于向客户端设置cookie。服务器可以使用cookie来识别和跟踪用户。 |
| Cache-Control | 指定了缓存策略,告诉客户端是否以及如何缓存响应。 |
| Location | 当服务器发送重定向响应(如 301 或 302)时,Location 头指定了重定向的位置。 |
| Server | 描述了响应服务器的软件或者版本信息。 |
| WWW-Authenticate | 用于401响应,指示客户端如何进行身份验证。 |
| Access-Control-Allow-Origin | 用于指定哪些域可以访问资源,用于CORS(跨源资源共享)策略。 |
5.3.3 响应体 #
- 响应体(Response Body)是HTTP响应中的一部分,它包含了服务器返回的数据。这些数据可能是HTML页面、JSON对象、二进制数据(如图片或文件)等
- 响应体的格式和内容取决于请求的资源和服务器的处理。例如,当你访问一个网页时,服务器通常会返回一个HTML文档作为响应体。当你调用一个API时,服务器可能会返回一个JSON对象作为响应体
- 响应体的数据类型通常由"Content-Type"响应头指定。例如,如果响应体包含JSON数据,那么"Content-Type"头的值可能会是"application/json"
- 在某些情况下,响应可能不包含响应体。例如,对于状态码为204 ("No Content") 的响应和HEAD请求的响应,就不包含响应体
5.4. 请求响应演示 #
5.4.1 HTTP服务器 #
// 引入所需的模块
const http = require('http');
const url = require('url');
const fs = require('fs');
const path = require('path');
// 创建用户列表
let users = [];
// 创建HTTP服务器并定义请求处理逻辑
const server = http.createServer(async (req, res) => {
// 解析请求URL
const parsedUrl = url.parse(req.url, true);
const { pathname } = parsedUrl;
const { id } = parsedUrl.query;
// 判断请求路径并处理
if (pathname === '/') {
// 如果请求根路径,返回'hello world'
res.end('hello world');
} else if (pathname === '/users') {
// 如果请求用户列表,根据请求方法进行处理
switch (req.method) {
case 'POST':
// 如果是POST请求,创建新用户并添加到列表
const newUser = await getRequestBody(req);
newUser.id = users.length + 1;
users.push(newUser);
res.end('用户创建成功');
break;
case 'DELETE':
// 如果是DELETE请求,从用户列表中移除指定的用户
if (id) {
users = users.filter(user => user.id !== parseInt(id));
res.end('用户删除成功');
}
break;
case 'PUT':
// 如果是PUT请求,更新用户列表中的指定用户信息
if (id) {
const updateUser = await getRequestBody(req);
users = users.map(user => user.id === parseInt(id) ? {
...user,
...updateUser
} : user);
res.end('用户更新成功');
}
break;
case 'GET':
// 如果是GET请求,返回指定的用户信息或整个用户列表
if (id) {
const user = users.find(user => user.id === parseInt(id));
res.end(JSON.stringify(user));
} else {
res.end(JSON.stringify(users));
}
break;
default:
// 如果请求方法不被支持,返回错误信息
res.end('很抱歉,暂时不支持该请求方法');
break;
}
} else {
// 如果请求其他路径,尝试作为文件路径处理并返回文件内容
const ext = path.extname(pathname);
const filePath = path.join(__dirname, pathname);
if (ext === '.html' || ext === '.js' || ext === '.css') {
// 如果是html、js或css文件,尝试读取并返回
fs.readFile(filePath, 'utf8', (err, data) => {
if (err) {
// 如果文件不存在,返回404错误
res.statusCode = 404;
res.end('Not found');
} else {
// 如果文件存在,设置正确的Content-Type并返回文件内容
res.setHeader('Content-Type', getContentType(ext));
res.end(data);
}
});
} else {
// 如果路径不是文件路径或用户列表,返回错误信息
res.end('Invalid path');
}
}
});
// 根据文件扩展名返回对应的Content-Type
function getContentType(ext) {
switch (ext) {
case '.html':
return 'text/html';
case '.js':
return 'text/javascript';
case '.css':
return 'text/css';
default:
// 当无匹配扩展名时,返回通用的类型
return 'text/plain';
}
}
// 处理请求体,解析为JSON对象
function getRequestBody(req) {
return new Promise(resolve => {
// 初始化请求体字符串
let body = '';
req.on('data', chunk => {
// 当有数据到来时,添加到请求体字符串
body += chunk;
});
req.on('end', () => {
// 当所有数据接收完毕,解析为JSON并返回
resolve(JSON.parse(body));
});
});
}
// 启动服务器并监听3000端口
server.listen(3000, () => console.log(`Server is listening on port 3000`));
5.4.2 HTTP客户端 #
5.4.2.1 curl #
- curl 是一个强大的命令行工具,它可以用来传输或接收数据
- -d 参数用来指定 POST 数据
- -X 参数用来指定 HTTP 方法
- -H 参数用来指定 HTTP 头
5.4.2..2 创建一个新用户(POST请求) #
curl -v -X POST -H "Content-Type: application/json" -d '{"name":"zhu","age":16}' http://localhost:3000/users
5.4.2..3 更新用户信息(PUT请求) #
curl -v -X PUT -H "Content-Type: application/json" -d '{"name":"feng","age":17}' http://localhost:3000/users?id=1
5.4.2..4 查询用户信息(GET请求) #
curl -v -X GET http://localhost:3000/users?id=1
5.4.2..5 删除用户(DELETE请求) #
curl -v -X DELETE http://localhost:3000/users?id=1
6.浏览器解析绘制页面 #
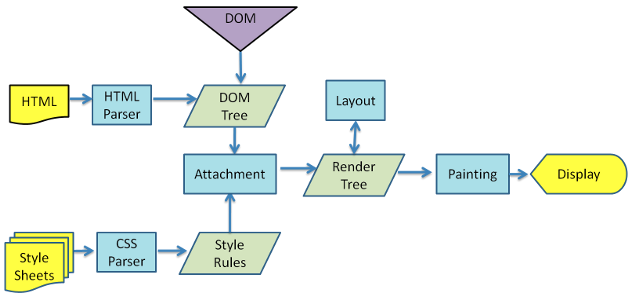
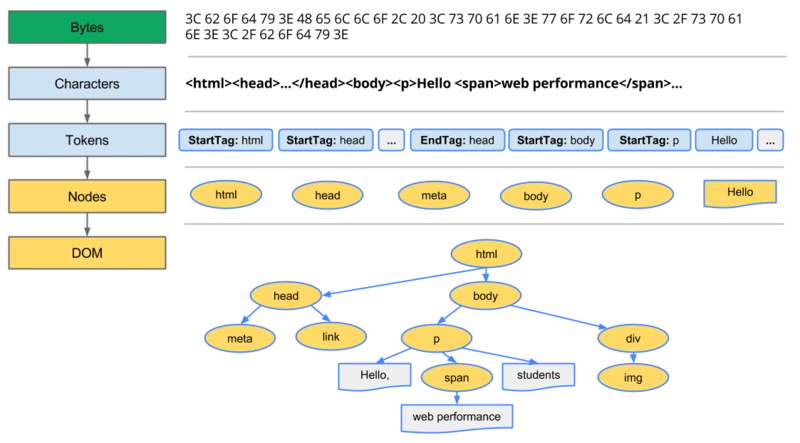
解析HTML:浏览器开始解析从服务器收到的HTML代码。这一步的过程被称为解析(Parse),它将HTML代码转换为一种叫做DOM(Document Object Model)的数据结构,DOM代表了网页的结构。
请求CSS和JavaScript:在解析HTML的同时,浏览器也会解析HTML代码中的链接,寻找CSS和JavaScript文件。当找到这些文件链接时,浏览器会再发出网络请求以获取这些文件。
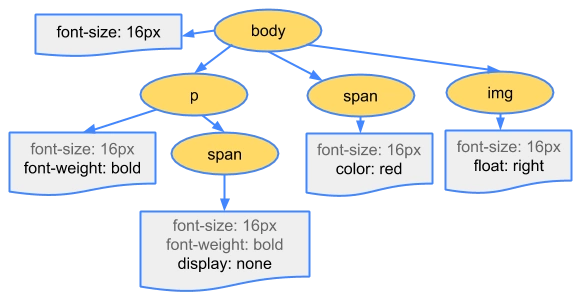
解析CSS:当CSS文件被下载完毕,浏览器将开始解析CSS代码。这一步将CSS代码转换为CSSOM(CSS Object Model)。CSSOM和DOM一起,构成了浏览器的渲染树(Render Tree)。
执行JavaScript:如果HTML文档中有JavaScript,浏览器将执行它。注意,JavaScript可能会修改DOM和CSSOM,所以执行JavaScript可能会导致浏览器重新渲染网页。
生成布局:当DOM和CSSOM都准备好之后,浏览器开始计算每个元素的几何位置,这个过程被称为布局(Layout)或重排(Reflow)。
渲染和绘制:最后,浏览器开始将每个元素绘制到屏幕上,这个过程被称为渲染(Painting)或重绘(Repaint)。

7. HTTP缓存 #
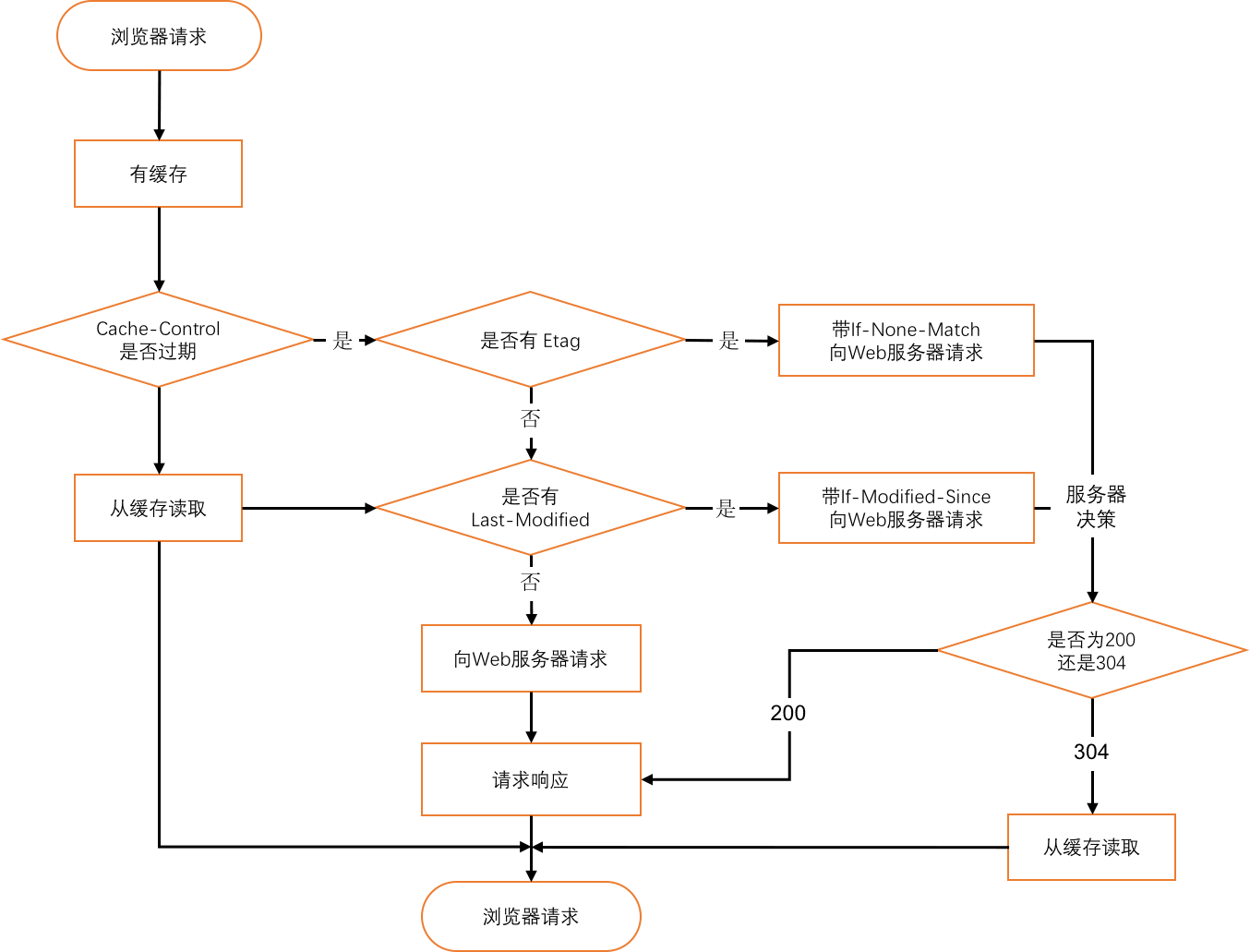
HTTP缓存主要通过两种方式来实现:强缓存和协商缓存。
1. 强缓存:
强缓存可以将请求结果直接从缓存中获取,不需要与服务器进行交互。强缓存通过HTTP响应头中的Expires和Cache-Control字段来控制。
Expires: HTTP1.0中的字段,其值为服务器返回此响应时的时间加上设定的过期时间。如果再次请求时,客户端的系统时间小于Expires的值,就会使用缓存。Cache-Control: HTTP1.1中新增的字段,它有多个参数,最常用的有max-age(指定缓存存储的最大周期,超过这个时间缓存被认为过期),no-cache(需要使用协商缓存来验证缓存数据),no-store(所有内容都不会被缓存)等。
2. 协商缓存:
当强缓存失效后,浏览器就会和服务器进行交互,以验证资源是否发生变化。如果资源没有变化,服务器会返回304状态码,通知客户端使用本地缓存;如果资源有变化,服务器会返回新的资源以及200状态码。协商缓存通过Last-Modified/If-Modified-Since和ETag/If-None-Match这两对HTTP头字段来控制。
Last-Modified和If-Modified-Since:Last-Modified在响应头中,表示资源的最后修改时间。If-Modified-Since在请求头中,告诉服务器若资源在此时间后修改过,请返回新的资源,否则返回304。ETag和If-None-Match:ETag在响应头中,是服务器为每个资源生成的唯一标识符。If-None-Match在请求头中,如果服务器的ETag值和If-None-Match的值不匹配,则说明资源有变化,服务器返回新的资源和200,否则返回304。
关于硬盘缓存与内存缓存:
硬盘缓存(Disk Cache):浏览器会将缓存文件保存在用户硬盘的特定目录下。当用户下次请求相同的资源时,浏览器将从硬盘上读取并加载资源。
内存缓存(Memory Cache):浏览器会将正在使用或者近期使用的资源保存在内存中,以便快速访问。内存缓存的优点是读取速度快,但缺点是占用系统内存,并且在浏览器关闭后缓存将被清空。
对于同一个资源,内存缓存的优先级高于硬盘缓存。如果内存中已有缓存,那么将直接从内存中读取,否则才会去硬盘中查找。
8. 本地存储 #
浏览器的本地存储主要有以下几种方案:Cookie、LocalStorage、SessionStorage、IndexedDB 和 Web SQL(已废弃),以下是这些本地存储方案的一些细节和示例代码:
1. Cookie
Cookie 是由服务器设置的,可以通过HTTP头发送到浏览器,浏览器也会在每次请求同一服务器时发送该Cookie。Cookie最初是为了保存会话(Session)信息设计的,但随着时间的推移,它也被用于各种其他目的。
示例代码:
// 设置cookie
document.cookie = "username=John Doe; expires=Thu, 18 Dec 2023 12:00:00 UTC; path=/";
// 获取cookie
var x = document.cookie;
2. LocalStorage
LocalStorage 是HTML5引入的一种新的客户端存储机制,它允许在用户的浏览器上保存Key/Value的字符串对,它们在浏览器关闭后依然存在。LocalStorage和SessionStorage的区别在于数据的生命周期:LocalStorage的数据在浏览器关闭后依然存在,除非用户清除浏览器数据。
示例代码:
// 设置 localStorage
localStorage.setItem('myKey', 'myValue');
// 获取 localStorage
var result = localStorage.getItem('myKey');
3. SessionStorage
SessionStorage与LocalStorage非常相似,都是保存Key/Value的字符串对,但SessionStorage的数据在浏览器关闭后会消失。
示例代码:
// 设置 sessionStorage
sessionStorage.setItem('sessionKey', 'sessionValue');
// 获取 sessionStorage
var sessionResult = sessionStorage.getItem('sessionKey');
class ExpiringLocalStorage {
setItem(key, value, expiryInMinutes) {
const now = new Date();
// 将value和expiry封装在一起存入localStorage,expiry为有效时间的时间戳
const item = {
value: value,
expiry: now.getTime() + expiryInMinutes * 60 * 1000,
};
localStorage.setItem(key, JSON.stringify(item));
}
getItem(key) {
const itemStr = localStorage.getItem(key);
// 如果不存在返回null
if (!itemStr) {
return null;
}
const item = JSON.parse(itemStr);
const now = new Date();
// 比较现在的时间和存入的有效时间
if (now.getTime() > item.expiry) {
// 如果过期了,就删除key并返回null
localStorage.removeItem(key);
return null;
}
return item.value;
}
}
// 使用方式
let storage = new ExpiringLocalStorage();
storage.setItem('test', 'hello world', 1); // 1分钟后过期
console.log(storage.getItem('test')); // 如果在1分钟内输出 "hello world", 否则输出 null
存储方案的对比:
| 存储方式 | 存储大小 | 是否发送到服务器 | 生命周期 |
|---|---|---|---|
| Cookie | ~4KB | 是 | 可设置 |
| LocalStorage | ~5MB | 否 | 除非手动清除,否则永久存在 |
| SessionStorage | ~5MB | 否 | 浏览器关闭时消失 |
9. Cookie #
- Cookie是由网络服务器保存在用户计算机中的一小块数据,主要用于保持服务器和用户浏览器之间的状态。其功能包括存储会话信息、用户设置、购物车内容等
- 以下是Cookie的一些关键特性和用法:
- 保存状态信息:当用户浏览一个网站时,他们可能需要登录,选择某些选项,或进行其他需要保存状态的活动。Cookie可以在用户的机器上存储这些信息,以便在他们返回时能够提供相同的个性化体验
- 跟踪用户:Cookie也可以用于跟踪用户在网站上的行为,例如哪些页面被访问了,这些信息可以用于分析用户行为或定位广告
- 会话管理:对于登录网站、购物车、游戏分数或其他需要保持跨多个会话的信息,Cookies是非常有用的
- 个性化:用户可能会看到某个网站保存了他们的设置(例如用户名、语言、地点、主题等),这使得网站在下次访问时可以提供个性化的体验
- Cookie主要通过HTTP的
Set-Cookie头部字段来设置,可以通过JavaScript的document.cookie属性来读取和设置
工作流程
- 设置 Cookie:当用户第一次访问一个网站,服务器会通过 HTTP 响应头中的
Set-Cookie字段来设置一个或多个 Cookie。一个Set-Cookie可能看起来像这样:Set-Cookie: id=1;。这将在用户的浏览器中设置一个名为 "id" 的 Cookie,值为 "1" - 发送 Cookie:一旦设置了 Cookie,浏览器将在后续的每个请求中将 Cookie 附加到 HTTP 请求头中,发送到同一服务器。这通常用于识别用户,以便服务器可以提供个性化的响应
const http = require('http');
const server = http.createServer((req, res) => {
// 读取cookie
let cookies = req.headers['cookie'];
console.log('Cookies: ', cookies);
// 设置cookie
res.setHeader('Set-Cookie', ['id=1', 'age=18']);
res.statusCode = 200;
res.end('hello');
});
server.listen(3000, () => console.log(`Server is listening on port 3000`));
10. 资源加载 #
浏览器加载和执行 HTML 中引入的 JavaScript 和 CSS 资源的过程如下:
请求 HTML 页面:首先,浏览器发出请求并接收 HTML 页面。HTML 页面是纯文本文件,包含了页面的结构和内容,以及对其他资源(如 JavaScript 和 CSS 文件)的引用。
解析 HTML:浏览器开始解析 HTML,将其转换为 DOM (Document Object Model)。DOM 是 HTML 元素的树形结构,用于表示页面内容。在解析过程中,浏览器会查找到
<link>和<script>标签,并知道需要加载额外的资源。请求 JavaScript 和 CSS:对于每一个
<link>或<script>标签,浏览器都会发起新的 HTTP 请求来获取这些文件。这些请求是异步的,意味着浏览器不会等待一个文件下载完成后再去下载下一个文件,而是同时进行下载。处理 CSS:CSS 文件被下载后,浏览器将它们解析成 CSSOM(CSS Object Model,CSS对象模型),它是 CSS 文件的树形表示。CSSOM 用于确定页面中每个元素的样式。这个过程称为渲染阻塞,因为在 CSSOM 构建完成前,浏览器无法进行下一步的渲染工作。
处理 JavaScript:对于 JavaScript,情况就有些不同。默认情况下,当浏览器遇到一个
<script>标签时,它会阻塞 HTML 的解析,直到 JavaScript 文件被下载和执行完毕。这是因为 JavaScript 可以修改 DOM 结构,因此浏览器需要等待 JavaScript 执行完成,以防止构建错误的 DOM。但是,你可以通过添加async或defer属性来改变这种行为。async:异步加载和执行 JavaScript 文件。HTML 解析和 JavaScript 加载同时进行,但是一旦 JavaScript 文件加载完成,HTML 解析会暂停,以便执行 JavaScript。defer:延迟执行 JavaScript 文件,直到 HTML 解析完成。和 async 不同,它保证了脚本按照指定的顺序执行。
渲染页面:当所有的 CSS 和 JavaScript 文件都加载和解析完成后,浏览器开始渲染页面,这包括创建渲染树(由 DOM 和 CSSOM 组成)、布局(确定每个元素的位置和大小)和绘制(将每个元素绘制到屏幕上)。对于 JavaScript,如果脚本修改了 DOM 或 CSSOM,浏览器可能需要重新进行部分或全部渲染过程。
